Datenbankaufbau : Skript

Laufkäfer, Käferdatenbank South
Kensington
Kapitel 7: Formate in bibliographischen
Datenbanken
von Margarete Payer & Alois Payer
(mailto: payer@hdm-stuttgart.de
Zitierweise / cite as:
Payer, Margarete <1942 - >: Datenbankaufbau :
Skript / Margarete Payer & Alois Payer. -- Kapitel 7:
Formate in bibliographischen Datenbanken. -- Fassung vom 2016-03-27. -- URL: http://www.payer.de/dbaufbau/dbauf07.html.
-- [Stichwort].
Überarbeitungen: 1997-05-15; 2001-05-27; 2002-05-14; 2009-03-14;
2010-03-14 [Aktualisierung wegen MALIS]; 2013-06-20; 2015-02-27 [Überarbeitung];
2016-03-27 [Aktualisierung]
Anlass: Lehrveranstaltungen an der HdM Stuttgart; MALIS (FH Köln,
ab 2015 TH Köln)
seit 2009
Unterrichtsmaterialien (gemäß § 46 (1) UrhG)
©opyright: Dieser Text steht der Allgemeinheit zur
Verfügung. Eine Verwertung in Publikationen, die über übliche
Zitate hinausgeht, bedarf der ausdrücklichen Genehmigung der Verfasserin.
Dieser Text ist Teil der Abteilung Datenbankaufbau
von Tüpfli's Global
Village Library
7.0. Übersicht
- 7.1. Warum braucht man ein Format?
- 7.2. Formatarten
- 7.3. Grundlage für ein Format
- 7.4. Aufbau von Formaten und Folgen
für den Datenaustausch
- 7.5. Kriterien bei der Auswahl eines
Formats
- 7.6. Welche Formate?
- 7.7. Bibframe
7.1. Warum braucht man ein Format?
Um Titelaufnahmen in Katalogdatenbanken zu erfassen, zu
speichern und zu verwalten, benötigt man Vorschriften zur Strukturierung des
Datensatzes: ein Datenformat (kurz "Format"). Ein Format kann aus mehreren
Dateien bestehen.
Als Format bezeichnet man die Absprachen
(Konventionen)
- zur Erfassung
- maschinellen Interpretation (z.B.
Nichtsortierzeichen)
- und Verarbeitung von Katalogisierungsdaten
|
7.2. Formatarten
Für die Bearbeitung unterscheidet man Intern- und
Externformat:
- Internformat:
Format, in dem die Daten so abgelegt sind, dass sie mit den
Programmen eines bestimmten Anwenders weiterverarbeitet werden
können. Durch Berücksichtigung von Hardware- und
Software-Erfordernissen können Programmieraufwand und Maschinenzeit
bei der Verarbeitung der Daten wesentlich beeinflusst werden. Das
Internformat kann vom Computer direkt verarbeitet werden.
- Externformat (auch Erfassungsformat, Kategorienschema
genannt), äußere Struktur :
Das Erfassungsformat enthält Aussagen über den
inhaltlichen Aufbau, d.h. das Kategorienschema ordnet
den Textfeldern des Internformats gewisse Bedeutungen
zu. Die Struktur dieses Schemas sollte so angelegt
sein, dass es für den Erfassenden möglichst einfach
anwendbar ist. Im folgenden wird immer von
Externformaten die Rede sein.
In der Anwendung unterscheidet man Institutionen spezifische
Formate und Austauschformate (nationale und internationale)
- Austauschformate sind in erster Linie dafür
gedacht, Daten zwischen verschiedenen Systemen
auszutauschen d.h. sie enthalten u.a. Absprachen zur Übertragung der Daten.
Auf deutscher Ebene wurde lange Zeit MAB [Maschinelles Austauschformat für
Bibliotheken] genutzt. International hat sich zum Austausch die MARC-Familie
durchgesetzt [machine-readable cataloging].
- Austauschformate werden aber auch als Format
für spezielle Institutionen benutzt. So
liegen heute in deutschen Verbünden meist MARC-Strukturen zu Grunde. Dabei geht es vor allem darum
das Format so zu erweitern, dass spezifische
Aufgaben eines Verbundes zu erfüllen sind.
7.3. Grundlage für ein Format
Als Grundlage für ein Format galt bisher das jeweilige Regelwerk für die
Erschließung (formale und sachliche Erschließung). Eine nicht ganz einfache
Aufgabe ist es, die Vorschriften eines neuen Regelwerks in ein bestehendes
Format einzuarbeiten (s. unten unter MARC 21)
Ein Regelwerk schreibt mindestens vor:
- welche Informationen erfasst werden
müssen
- welche Zugangspunkte angeboten werden
sollen
- in welcher Form diese Zugangspunkte angeboten
werden sollen
- in neueren Regelwerken: welche Verknüpfungen
bzw. Beziehungen sollen angeboten werden
|
Darauf aufbauend entwickelt man ein Pflichtenheft: ein
Datenformat muss u.a. folgendes leisten:
- insbesondere muss aufgeführt werden:
- die vom Regelwerk geforderten
Elemente müssen erfassbar sein, indem man die Elemente
Kategorien (Feldern) zuordnet
- Elemente, die als Sucheinstiege
dienen, müssen entsprechend aufbereitet sein
- Geforderte Verknüpfungen müssen
funktionieren, z.B. Verknüpfungen zu Normdateien, aber auch
Verknüpfungen zwischen Datensätzen innerhalb einer Datei
(z.B. Monografie zur Schriftenreihe)
- Mehrfacheinträge müssen geregelt
werden, z.B. durch die Möglichkeit der Feldwiederholung
- Regeln zur Ordnung sollten
eingehalten werden, Festlegen der verwendbaren Zeichen
- Für den OPAC ist zusätzlich ein
Pflichtenheft zu erstellen: u.a.
- für die Anzeige der Daten auf dem
Bildschirm
- für die Benutzerführung
- für Hilfsbildschirme
|
Eine gute Einführung in das Thema
findet man: Eversberg, Bernhard: Was sind und was sollen bibliothekarische
Datenformate. - WWW-Ausgabe. - 1999. - URL:
http://www.allegro-c.de/formate/formate.htm -- Zugriff 2016-03-26. Hilfreich
ist der Bezug auf das OSI-Referenzmodell [Open Systems Interconnection] der ISO
[International Organization for Standardization].
7.4. Aufbau von Formaten und Folgen für
den Datenaustausch
Die heutigen allgemein anerkannten Formate kann man als
analytische Datenformate beschreiben, d.h. die Titelaufnahmen
sind in elementare Kategorien oder Felder aufgeteilt. Anders
ausgedrückt: die Titelaufnahme ist in einzelne Elemente
aufgeteilt, die je eine sachliche Einheit darstellen.
Die Abfolge der Elemente wird unterschiedlich gehandhabt.
Grundsätzlich kann man sich an der Reihenfolge in einer
Titelaufnahme nach ISBD und mit traditionellen Köpfen und
Nebeneintragungen orientieren wie die MARC-Formate. Man kann aber
auch sachlich zueinander passende Elemente in Segmenten anordnen
wie MAB (Maschinelles Austauschformat für Bibliotheken,
das deutsche Austauschformat) und wie UNIMARC (ein internationales
Austauschformat). Diese Abfolge ist für einen Datentausch
unerheblich.
Schwierig wird es erst für den Austausch, wenn ein Format in
einem Feld oder in einem Unterfeld mehrere bibliographische
Elemente zusammenfasst, wie es MARC tut. MAB nimmt pro variablem
Feld im allgemeinen nur ein bibliographisches Element
z.B. Feld 245 in USMARC ohne Unterscheidung, was der
Paralleltitel ist, und MAB mit einem eigenen Feld für den
Paralleltitel.
Es ist auch unterschiedlich festgelegt, ob eine Aufnahme in
einem Datensatz oder in mehrere aufgeteilt werden soll. So werden
in US-MARC sämtliche Angaben zum mehrbändigen Werk in einem
Satz angegeben, MAB bildet in solchen Fällen mehrere
zueinander gehörende Sätze (Hauptsätze, Untersätze und in MAB 1 Nachsätze); diese Sätze stehen in einem hierarchischen
Verhältnis zueinander (im Nachsatz standen Ansetzungsformen für
Nebeneintragungen von beigefügten und enthaltenen Werken).
UNIMARC ist flexibel.
Neben diesen Problemen für die Umsetzung muss man u.a. noch fertig werden
mit unterschiedlichen Zeichencodes, unterschiedlichen Steuerzeichen (z.B.
Nichtsortierzeichen) und unterschiedlichen Verknüpfungsstrukturen. (Die
größten Probleme für den Austausch bereiten allerdings nicht die Formate
sondern die dahinterliegenden Regelwerke.)
Die allgemein anerkannten Formate orientieren sich heute im allgemeinen an
nationalen bzw. internationalen Normen. Unabdingbar für einen
Austausch ist das Einhalten bestimmter Vorschriften (Protokolle)
-- heute oft noch eine normierte Struktur der Daten auf
Magnetbändern, mehr und mehr aber normierte Strukturen für den
Austausch über File transfer. Dafür wurde die ISO Norm 2709
Documentation -- Format for bibliographic information
interchange on magnetic tape (vgl. DIN 1506) entwickelt.
Danach bestehen die Datensätze je aus 3 Teilen:
- record label (festes Feld, 192 Bytes lang) auch
leader, Satzkennung genannt
- directory (Inhaltsverzeichnis) (12 Bytes je
Eintragung)
- variable fields (variable Datenfelder)
Record label (wie der Vorspann zu einem Film)
enthält die für die Identifizierung und Bearbeitung des Satzes
wichtigen Angaben und solche Daten, die im direkten Zugriff
stehen sollen z.B. Länge des Satzes der laufenden
Identifikationsnummer der Austauscheinheit
Inhaltsverzeichnis wie die Seitenangabe in einem Buch. (MAB 2 verzichtet
inzwischen auf das Inhaltsverzeichnis.)
Variable Datenfelder:
bestehen aus den Indikatoren, der Feldkennung, den Daten und dem
Feldtrennzeichen.
Übereinstimmend ist damit die logische und physikalische
Gliederung der bibliographischen Daten, aber wie oben schon
angedeutet nicht die Struktur des Dateninhalts.
Beispiele aus einem MARC-record: [¶=Feldendezeichen]
Leader: 0-23
00515namØØ2200145ØØØØØØØ
Directory: 24-144
001001300000008004100013050001800054082001600072100002300088
usw.
Variable data fields:
- LC Call Number:
0Ø$aHD9560.5$b.S8¶
- Main entry:
10$aSugarman,$Stephen¶
- Title:
1Ø$aPetroleumØindustryØhandbook$ceditedØbyØStephenØSugarman¶
- usw. für Imprint, Collation, General Note, Subject
Heading
7.5. Kriterien bei der Auswahl eines
Formats
Im Zeitalter der Vernetzung von Bibliotheken wird man
wohl selten die Möglichkeit haben ein Format auszuwählen, denn zumindest für die
Bibliotheken innerhalb der deutschen (und österreichischen) Verbünde ist das
eine bibliothekspolitische Frage. Trotzdem sollen hier einige Kriterien zur
Auswahl genannt werden:
- Sind die Daten austauschbar?
Sind internationale Standards eingehalten?
- Können die Vorschriften des eigenen Regelwerks erfüllt
werden?
Sind z.B. hierarchische Aufnahmen bei mehrbändigen
Werken möglich? Sind Verknüpfungen vorgesehen?
- Sind genügend Felder für den lokalen Bedarf vorgesehen?
- Kann es für ein Mehrdateiensystem eingesetzt werden?
- Wie einengend ist es? bzw. ist es einfach erweiterbar?
z.B. gab es in MAB 1 immer nur eine bestimmte
Anzahl Felder für einzelne Elemente (10
Verweisungsfelder für einen Personennamen), in MARC
dagegen ist teilweise beliebige Wiederholung des
Feldes möglich.
- Welche Hilfen werden angeboten?
Listen von Codes, Beispielsammlung,
Anwendergremium, Mailing- Liste
- Sind alle gewünschten Materialien damit erfassbar?
- Ist die gewünschte sachliche Erschließung möglich?
- In welchem Format sind schon die meisten Daten erfasst?
-- damit man Fremdleistungen übernehmen kann.
- Wie sieht es mit der Anwendung im Web 2.0 aus?
7.6. Welche Formate?
Es geht hier um die Formate, die sich durchgesetzt haben. Abgesehen von den
selbstgestrickten Formaten für Kleinstanwender sind das die internationalen
Austauschformate (Formatfamilie MARC und das offizielle internationale Austauschformat
UNIMARC), die nationalen Austauschformate (z.B. bisher MAB für deutsche
und österreichische RAK-Anwender) und die Spezialformate der Verbünde, die
aber im allgemeinen eine Weiterentwicklung eines nationalen oder internationalen
Formats sind.
Ein neues Modell ist in Planung: s. 7.7 Bibframe
MARC (machine-readable cataloging) wurde seit 1966 von
der LoC benutzt, um ihre Daten per Magnetband an Bibliotheken zu
senden. Die Bibliotheken nutzten diese maschinenlesbaren Daten
zum Druck von Kartenkatalogen, Listenkatalogen, Bibliographien
u.ä. Diese Ausrichtung auf den Kartenkatalog haben die
amerikanischen MARC-Formate heute noch. Die LoC hatte im Laufe der
Zeit für verschiedene Materialien je verschiedene MARC-Formate
entwickelt, und zwar entsprechend den AACR für
- Monographien (books)
- fortlaufende Sammelwerke (serials)
- AV-Materialien (visual materials)
- Archivalien und Handschriften (archival and manuscripts
control)
- Karten (maps)
- Musikalien (music)
- computer files.
Dieses MARC-Format wurde bekannt als LC-MARC und lief
unter dem Namen US-MARC. Die MARC-Formate der großen US-Verbünde -- OCLC-MARC, RLIN-MARC, WLN-MARC -- sind voll
kompatibel mit US-MARC, daher war die Übernahme der Verbünde RLIN und WLN durch OCLC
erheblich erleichtert. Anfang der 80er Jahre wurde das Format an
AACR2 angeglichen. Damit waren gleichzeitig die Forderungen der ISBD's erfüllt.
Seit 1996 wurde Integrated MARC eingesetzt. Es handelt
sich um eine Zusammenfassung der nach Materialien getrennten
MARCFormate, da es teilweise schwierig war, eine Vorlage einem
bestimmten Format zuzuordnen z.B. was nimmt man, wenn die Vorlage
eine Zeitschrift in Mikroform ist?
US-MARC in seiner Weiterentwicklung MARC 21 ist vor allem dadurch so interessant, weil damit
große Datenbestände erfasst sind -- nämlich nicht nur die
Daten der LoC, sondern auch die Datenbank von OCLC, im Februar 2015 über
332 Millionen Titel (mit
unzähligen Millionen
von Bestandsnachweisen). [s.
http://www.oclc.org/worldcat. - Zugriff 2015-02-09]
UK-MARC (United Kingdom) wurde von der British Library (BL) für die
British National Bibliography entwickelt, und gerade in dieser
speziellen Zielsetzung lagen dann auch die Unterschiede zu US-MARC.
Die Unterschiede zwischen US-MARC und UK-MARC bestanden u.a.
darin, dass UK-MARC weiter untergliedert. Z.B. werden
Paralleltitel in einem eigenen Unterfeld angegeben (245 subfield
$k). Auch sieht UK-MARC im Unterschied zu US-MARC hierarchisch
gegliederte mehrbändige Werke (analytische Levels) vor. s.
UK-MARC Manual p. 5/76 und p. 5/35 multilevel description.
Seit etwa 1996 bemühte man sich darum, die unterschiedlichen MARC-Fassungen
der USA, Kanadas und Großbritanniens in Übereinstimmung zu bringen. Z.B. hat
man sich inzwischen auf gleiche Codes geeinigt (z.B. den Alpha-3-Code
[dreistelliger Ländercode] genommen).
Auf der Grundlage eines harmonisierten CAN/MARC - USMARC-Formats wurde
inzwischen das UK-MARC eingeschlossen. Man erwartet, dass weitere MARC-Formate
entsprechend überarbeitet werden. Die National Library of Canada begann mit dem
Einsatz 1999, die LoC im Januar 2000 und die BL 2001. Im Laufe des Jahres
2009 ist MARC 21 als Austauschformat für die deutschen Verbünde und die DNB
übernommen worden.
MARC 21 besteht aus folgenden Teilen:
Eine hervorragende Einführung in MARC 21 findet man unter
dem Titel:
Understanding MARC bibliographic : machine-readable
cataloging / written by Betty Furrie in conjunction with the Data Base
Development Department of The Follett Software Company. - 8. ed. - Washington,
D.C. : Library of Congress, 2009. - URL:
http://www.loc.gov/marc/umb/ . - Zugriff am 2016-03-26.
Alle Formatteile und weiteres zu MARC 21 findet man
unter: http://www.loc.gov/marc/ Zugriff
2016-03-26. Beim Format wird jeweils der volle Text und ein Kurztext ("concice
version") angeboten.
Als Beispiel für das Format für bibliografische Daten:
einige wichtige Felder (tags) mit ihren beiden Indikatoren und Unterfeldern
(nicht jedes Feld hat Indikatoren oder benötigt beide Indikatoren). Felder
können wiederholbar sein: R bzw NR für nicht wiederholbar. Sind keine
Indikatoren vorhanden, kennzeichnet man das mit ##; Unterfelder werden mit $ und
einem Buchstaben oder einer einstelligen Zahl eingeführt. Im Folgenden ist
nur angegeben, was man für eine einfache Titelaufnahme benötigt.
010 ## $a : Nummer des Datensatzes
020 ## $a ISBN : $c z.B. der Preis. z.B.: 020 ## $a
3123423560
100 Haupteintragung für den 1. Verfasser, daher nicht
wiederholbar. Es gibt nur den Indikator 1 mit 3 Festlegungen: 0 = Vorname (z.B.
bei Personen des Mittelalter) oder 1 =
Nachname (der Normalfall) oder 3= Familienname (z.B. "Bach-Familie")
100 1# $a Personennamen, $d Lebensdaten. z.B.: 100 1# $a
Müller, Max
240 Einheitstitel (Uniform title), der nicht die
Haupteintragung erhält: nicht wiederholbar; 2
Indikatoren: der 1. Indikator sagt an, dass der Titel auf dem Bildschirm gezeigt
wird; der 2. Indikator (0 - 9) zeigt an, wie viele Stellen beim Sortieren
übergangen werden müssen
240 10 $a Einheitstitel; $l Sprache des Werks; $f Datum
des Werks
245 Angabe des Sachtitels und Verfasserangabe. Der 1.
Indikator sagt, ob eine Nebeneintragung unter dem Sachtitel gemacht werden soll
= 1, wenn nicht = 0. Der 2. Indikator zeigt an, wie viele Stellen beim Sortieren
übergangen werden müssen. Es gibt eine Reihe von Unterfeldern, u.a. $a =
Hauptsachtitel, $b = Zusatz, $c = Verfasserangabe
245 10 $a Hauptsachtitel : $b Zusatz zum Sachtitel / $c
Verfasserangabe.
z.B.: 245 14 $a Die Schwarzbären in Kalifornien : $b
Ernährung aus Mülltonnen ; ein Problem / $c M. Müller ; F. Meier
250 ## $a Ausgabebezeichnung. z.B. 250 ## $a 25. Version
260 ## $a Erscheinungsort (wiederholbar) : $b Verlag
(wiederholbar), $c Erscheinungsdatum (wiederholbar)
z.B.: 260 ## $a Ofterdingen : $b Reyap, $c 1987
300 ## $a Umfangsangabe : $b Illustrationsangabe; $c
Format (in cm). z.B.: 300 ## $a 555 S. : $b zahlr. Ill., Kt.
490 Angabe der Serie: wenn man eine Nebeneintragung
unter der Serie haben will, muss zusätzlich ein Feld 8XX belegt werden und als
Indikator 1 die 1; wenn nicht Indikator 1 mit der Angabe 0. Der 2. Indikator ist
nicht belegt.
490 1# $a Gesamttitel ; $v Zählung. z.B.: 490 0# $a
Bärenreihe ; $v 36
500 ## $a allgemeine Fußnote
600 : die 600er Felder enthalten verschiedene Arten von
Schlagworten z.B.
600 10 $a Subject added entry - Personal name (Indikator
1 nennt den Typ des Verfassernamens: 1 = moderner Personenname; der Indikator 2
nennt das Sacherschließungssystem: 0 = LoC Subject Heading)
700 : die 700er enthalten die Nebeneintragungen z.B.
700 1# $a Personennamen, $d Lebensdaten, $e Relator term
(Indikator 1 s. oben bei Feld 100)
z.B.: 700 1# $a Meier, Fritz:
MARC 21 wird zur Zeit fortgeschrieben, um Vorschriften
des neuen Regelwerks RDA zu ermöglichen. Es muss überprüft werden, welche
Felder, die nach den Regeln von AACR2 belegt sind, für die Regeln der RDA
genutzt werden können. Wegen des großen einzubringenden Altbestands kann man
Felder, Unterfelder, Codes usw. nicht uminterpretieren. Alle alten Felder usw.
müssen erhalten bleiben, sollten sie nicht mehr gebraucht werden, erklärt man
sie zu Feldern, die nicht angewendet werden dürfen. Wegen neuer Regeln müssen
neue Felder und/oder Unterfelder geschaffen werden, auch neue Codes werden
eingeführt. Z.B. sind bisher Attribute (z.B. Geburtsdatum) zu Namen im Feld für
die Namensansetzung angegeben worden, inzwischen hat man mit der Einführung
neuer Felder die Möglichkeit einer getrennten Erfassung der Attribute
geschaffen; z.B. "374 - Occupation (R)" und "376 - Family Information (R)" [Das
"R" steht für "wiederholbar", d.h. man kann mehrere Berufe und mehrere Familien
angeben.].
Weiterhin muss man die nach RDA über 400 möglichen
Beziehungen, die es zwischen Werk, Expression, Manifestation und Exemplar geben
kann, im Format darstellen. Die Beziehungen zwischen Namen und Ressourcen können
im Format aufgeführt werden. [Diese und weitere Angaben
findet man in "RDA in MARC" -Juli 2014. -
http://www.loc.gov/marc/RDAinMARC.html - Zugriff 2016-03-26]
Neben einer ganzen Reihe von weiteren nationalen MARC-Formaten
(z.B. CanMARC für Canada oder MalMARC für
Malaysia) soll INTERMARC hervorgehoben werden, weil man
mit diesem Format versuchte, ein allgemeines Austauschformat für
Westeuropa zu schaffen. Entwickelt wurde dieses Format von
Frankreich, Belgien und der Schweiz unter Beteiligung weiterer
westeuropäischer Länder. Angewendet wird INTERMARC
nur von der Bibliotheque Nationale, Paris, und zwar seit 1975.
1980 beschloss man, INTERMARC soweit wie möglich an das neue
internationale Format UNIMARC anzupassen, wodurch ein
Datenaustausch zwischen den beiden Formaten sehr erleichtert
wurde. UNIMARC wird von einer Mehrheit von französischen Bibliotheken genutzt.
[s.
http://www.bnf.fr/fr/professionnels/formats_catalogage.html - Zugriff
2016-03-26]
Ab 1977 begann die IFLA das Austauschformat
UNIMARC zu entwickeln [UNIMARC bibliographic in
kompletter und in verkürzter Form mit dem Stand 1.3.2000 unter: http://archive.ifla.org/VI/3/p1996-1/sec-uni.htm
Zugriff am 2016-03-26]. Es sollte die Voraussetzung für ein
internationales MARC-Netzwerk sein. Man schlug damals vor, dass Nationalbibliotheken mit bestehenden Formaten Programme
entwickeln, mit denen ihre Daten in UNIMARC umgesetzt werden
können, bzw. dass Nationalbibliotheken, die neu anfangen,
UNIMARC selbst oder eine eigene Anpassung an UNIMARC nutzen.
Praktisch kann man heute von einer ganzen Reihe von nationalen
bibliographischen Zentren Daten in UNIMARC erhalten, z.B. aus den
USA, Frankreich, (von der DNB zwischen Januar
1992 und 30. Juni 2013). Mehrere Nationalbibliotheken nutzen UNIMARC als
eigenes Erfassungsformat: z.B. Portugal, Griechenland, Indien, Italien, Rußland. Für das neue
italienische Regelwerk REICAT wird die Anwendung von UNIMARC vorgeschlagen.
Weitere Länder, in denen UNIMARC angewendet wird,: Algerien, Marokko, Tunesien.
Seit 2003 ist die Nationalbibliothek von Portugal verantwortlich für das
UNIMARC-Strategic-Programme [s.
http://www.ifla.org/about-unimarc -- Zugriff 2016-03-26]
Die neueste Ausgabe: UNIMARC manual : bibliografic
format / ed. by Alan Hopkinson. - 3. ed. - München : Saur, 2008. - 760 S. -
(IFLA series on bibliographic control ; 36) - ISBN 978-3-598-24284-7
Mit UNIMARC können die zur Zeit in Bibliotheken gängigen
Materialien katalogisiert werden, also auch Karten, Musikalien,
Tonträger, Graphika, AV-Materialien. Felder für Computerfiles
sind vorgesehen. Das Format ist für viele Regelwerke anwendbar,
setzt allerdings die Anwendung der verschiedenen ISBD's voraus.
UNIMARC schreibt aber nicht die Form der Ansetzung vor (die
Köpfe), weil in diesem Punkt die nationalen Regelwerke weit
auseinandergehen. Damit man aber auch z.B. Namensansetzungen
austauschen kann, sollte zusammen mit UNIMARC das UNIMARC
format for authorities angewendet werden. Dieses ist erst
1991 fertig gestellt worden.
Die neueste Ausgabe: UNIMARC manual : authorities
format / ed. by Mirna Willer. - 3. ed. - München : Saur, 2009. - 309 S. - (IFLA
series on bibliographic control ; 38) - ISBN 978-3-598-24286-1 [Eingearbeitet
sind Konzepte des FRAD-Modells (Functional requirements for authority data)
und des Statement of International Cataloguing Principles. ]
UNIMARC concise authorities format von 2009. URL:
http://www.ifla.org/files/assets/uca/unimarc_concise_authorities_format_2009.pdf
-- Zugriff 2016-03-26.
[Die folgenden Aussagen zu UNIMARC beziehen sich auf den
Stand von 1996:] Um auch für kleinere Institutionen flexibel in der Anwendung
zu bleiben, hat UNIMARC nur wenige Pflichtfelder. Mindestens muss im
bibliografischen Teil folgendes belegt sein:
- 001 Identifikationsnummer (record identifier)
- 100 Erfassungsdatum, Zeichensatz, Schrift
(general processing data)
- 101 Sprachbezeichnung (language of the work)
- 200 Titel (title)
- 801 Herkunft (originating source field)
Struktur:
Das Format ist gemäß ISO 2709 (Format for Bibliographic
Information Interchange) strukturiert:
In jeder Titelaufnahme werden 4 Teile unterschieden:
- leader, Satzkennung (record label)
- Inhaltsverzeichnis (directory)
- variable Kontrollfelder (variable control fields),
z.B. die Identifikationsnr.
- variable Datenfelder (variable data fields): 141
Felder, die jeweils Unterfelder haben können
Beispiel für ein variables Datenfeld in UNIMARC
Ø1$aSmith$bDavid$d1901-
Gliederung des Formats UNIMARC:
Das Format ist in Segmente -- die sogenannten Blöcke
-- aufgegliedert. Jeweils in einem 100er-Block werden inhaltlich
zusammengehörige Dinge zusammengefasst. Z.B. sind im 700er-Block
alle beteiligten Personen und Körperschaften vermerkt.
Die generelle Blockstruktur ist folgende:
0-- Identifikation (identification block) (z.B. ISBN,
Nationalbibliographie-Nummer usw.)
- 1-- Codierte Information (coded information)
(z.B. Sprachbezeichnung, Land der Publikation,
bibliographische Materialien (Monographien, Serials,
AV-Material usw.)
- 2-- Deskriptive Information (descriptive
information) (Einzelelemente der ISBD's)
- 3-- Fußnoten (notes)
- 4-- Verknüpfungen (linking entry)
- 5-- Weitere Titelangaben (related title) (z.B.
EST, Zitiertitel)
- 6-- Sacherschließung (subject analysis) (z.B.
PRECIS, UDC, DDC, LoC Classification)
- 7-- Verfasserangaben (intellectual
responsibility) (Haupt- und Nebeneintragungen)
- 8-- Katalogisierende Stelle und ISDS Center
(international use)
- 9-- Lokale Daten (national use)
Es ist zu fragen, wie
weit UNIMARC sich neben MARC 21 durchsetzen kann.
Von der IFLA wird das Format immer noch unterstützt (es
ist eine zentrale Aufgabe der IFLA ["IFLA Core activity UNIMARC"]). Immerhin
hatten sich die EG-Bibliotheken 1991 in Florenz entschlossen, UNIMARC zum gemeinsamen Austauschformat zu nehmen. Außerdem ist
eine auf UNIMARC basierende CD-ROM erschienen, die gemeinsame
Daten der sieben Nationalbibliotheken von Dänemark, Deutschland,
Frankreich, Großbritannien, Italien, Niederlande und Portugal
enthält. Im Jahr 2000 haben 22 Institutionen UNIMARC als Austauschformat
eingesetzt, 10 als Internformat und 17 werden als sonstige Anwender bezeichnet.
In der UNIMARC community wird zur Zeit die Anwendung des
Formats für das neue Regelwerk, die Übertragung in Webanwendungen und das
Zusammenwirken mit anderen Datenstandards diskutiert, auch wird dem Permanent
UNIMARC Committee empfohlen, dass sie die IFLA auffordert die Entwicklung einer
UNIMARC-Darstellung in RDF zu unterstützen :
s.: Dunsire, Gordon: UNIMARC, RDA and the
semantic web. - 2009. -
http://www.ifla.org/files/hq/papers/ifla75/135-dunsire-en.pdf - Zugriff
2015-02-26;
http://www.nlc.gov.cn/newen/fl/iflanlc/iclc/IFLAds/201012/P020101210594440572365.pdf
- Zugriff 2016-03-26
s.: Dunsire, Gordon und Mirna Willer: UNIMARC
and linked data. - In: IFLA Journal, Vol. 37,4. - 2011. - S. 314-326. -
URL:
http://www.ifla.org/files/assets/hq/publications/ifla-journal/ifla-journal-37-4_2011.pdf
- Zugriff 2016-03-26.
Das Maschinelle Austauschformat für Bibliotheken
hat seine Anfänge in der Deutschen Bibliothek ab 1973. Seit 1996 - nach einer
durchgreifenden Revision - wird MAB als MAB2 verbreitet. Zur Zeit wird
MAB2 durch MARC 21 abgelöst. Da aber vor allem nicht zu Verbünden gehörende
Bibliotheken noch auf MAB2 angewiesen sind, hatte die Deutsche Nationalbibliothek
versprochen, MAB2 noch bis 2015 zu pflegen. Der MAB-Dienst wird zum 30. Juni
2013 eingestellt.
MAB ermöglicht den Austausch von bibliographischen Daten, Norm- und
Lokaldaten. MAB2 war u.a. nötig geworden, um den Tausch in Online-Umgebungen
zu ermöglichen. Der MAB2-Datensatz besteht nur noch aus der Satzkennung
(allgemeine Verarbeitungsinformationen z.B. Satzlänge und allgemeine Angaben zum
Inhalt des Datensatzes z.B. ob es sich um eine neue Aufnahme handelt) und den
variablen Datenfeldern.
Die variablen Datenfelder bestehen aus der Feldkennung, einem Indikator, den
variablen Daten und dem Feldendezeichen. Je nach dem Inhalt des Feldes können
diese Felder wiederholbar sein, Unterfelder (wie in den MARC-Formaten) und
Teilfelder haben und obligatorisch sein.
MAB2 besteht aus fünf Formaten:
- MAB-Titel
- MAB-PND
- MAB-GKD
- MAB-SWD (Schlagwortnormdatei)
- MAB-LOKAL
Dazu kommen die provisorischen Teile: MAB-ADRESS (Adressen und
Bibliotheksdaten) und MAB-NOTAT (Klassifikation und Notation).
Die fünf Formate findet man in einer Online-Kurzreferenz-Version mit Stand
November 2001 unter URL: ftp://ftp.ddb.de/pub/mab/titelmab.txt . - Zugriff vom 2016-03-27. Diese
Version bietet eine inhaltliche Übersicht einschließlich der
jeweiligen Indikatoren und Kodierungen.
Als Besonderheit bei MAB sind die unterschiedlichen Satzarten zu nennen. In
MAB 2 handelt es sich um den Hauptsatz (=h), den Untersatz (=u) und den
Exemplarsatz (=e; Lokaldaten für ein Werk). Ein Hauptsatz ist ein selbständiger
Datensatz oder der oberste Datensatz in einer Hierarchie.
Während der Hauptsatz sich auf die Titelaufnahme einbändiger Werke, auf
Stücktitel und Gesamtaufnahmen bezieht, ist der Untersatz für die
Bandaufführung mehrbändiger Werke und fortlaufender Sammelwerke zu
nehmen. Namensdatensätze, Schlagwortdatensätze, Lokaldaten und
Pauschalverweisungsdatensätze sind ebenfalls Hauptsätze.
Gegenüber MARC 21 zeichnet sich MAB durch die schon im Format gegebenen
Verknüpfungsmöglichkeiten aus, wodurch die Anforderungen der FRBR leichter
erfüllt werden könnten:
- es können Beziehungen innerhalb einer MAB-Datei dargestellt werden:
- können mit Haupt- und Untersätzen bibliographische hierarchische
Strukturen abgebildet und verknüpft werden (z.B. mehrbändige begrenzte Werke
mit Bandaufführung, fortlaufende Sammelwerke mit Bandaufführung)
- können in MAB-Titel weitere Beziehungen unterschiedlicher Datensätze
durch Verknüpfung hergestellt werden (Stücktitel - Gesamttitel;
unselbständig erschienenes Werk - selbständig erschienenes Werk;
reziproke/nichtreziproke Beziehungen zwischen Werken z.B. bei
Parallelausgaben)
- es können Beziehungen zwischen Datensätzen unterschiedlicher MAB-Dateien
hergestellt werden; z.B. Personennamensdatensatz zu dem entsprechenden
Titeldatensatz.
7.7. bibframe
Bibframe (Bibliographic Framework) ist das neue Model,
das die bisherigen Formate ersetzen soll. Das Model soll nicht auf ein
bestimmtes Regelwerk ausgerichtet sein.
Begründung für den neuen Ansatz:
- Mit dem 50 jährigen MARC-Format können zwar
die Bibliothekskataloge weltweit ihre Daten austauschen, aber es ist ein
Sonderweg.
- Das neue Regelwerk RDA kann nicht vollständig in MARC
dargestellt werden, insbesondere können nicht alle Anforderungen der FRBR
erfüllt werden.
- Die Beobachtung, dass das Web sich von einem
Netzwerk verknüpfter Dokumente zu einem Netzwerk verknüpfter Daten
entwickelt.
Das Ziel:
- Bibliotheksdaten sollen ein Teil des Webs werden,
d.h. sie sollen in die allgemeine Informationswelt integriert werden. D.h.
es müssen die Bibliotheksdaten in einer Form angeboten werden, die
üblicherweise von Suchmaschinen verstanden wird
- die Beziehungen der Bibliotheksdaten zu Daten
außerhalb von Bibliotheken sollen betont werden
- die Beschreibung von Ressourcen außerhalb der
Bibliothekswelt sollen ermöglicht werden (Ressourcen aus Archiven, Museen
usw.)
- traditionelle Aufgaben müssen ebenso erfüllt werden:
Datenaustausch zwischen Bibliotheken und Übernahme der alten MARC-Daten
- Ermöglichung von maschineller Interpretation von
Entitäten. Dazu ist eine eindeutige Identifizierung von Entitäten und das
Nutzen von maschinenfreundlichen Identifiern nötig
Basis:
- Linked Open Data
- RDF [Resource Description Framework], Standard des
World Wide Web Consortiums zur Beschreibung von Metadaten. Wichtig dabei:
RDF/XML
Verantwortliche Organisationen u.a.:
- Library of Congress. Von der LoC ging im Mai 2011
die Initiative für ein neues Model aus.
- OCLC
- Deutsche Nationalbibliothek
Besonders herausgearbeitet werden drei Forderungen:
- Es soll klar unterschieden werden zwischen dem
begrifflichen Inhalt und seiner physikalischen Erscheinung (also zwischen
der abstrakt gedachten Entität Werk und seiner Manifestation (!Bibframe
verwendet "instance" statt "manifestation").
- Der Schwerpunkt soll auf eindeutig zu
identifizierenden Informations-Entitäten liegen (z.B. Verfasser).
- Die Beziehungen zwischen und innerhalb der Entitäten
sollen hervorgehoben werden.
In einer vernetzten Welt ist es wichtig, dass man
Bibliotheksdaten so zitiert, dass nicht nur zwischen dem gedanklichen Werk
(Titel und Verfasser) und seinen physikalischen Details seiner Manifestation
unterschieden wird, sondern auch dass die Entitäten, die am Verfassen einer Ressource
beteiligt sind, und die Begriffe, die mit der Ressource verbunden sind,
mitgeführt werden. Die bisherige Praxis, dass Katalogeinträge unabhängig von
anderen Einträgen zu verstehen sind, wird aufgehoben. Insgesamt wird der
Schwerpunkt bei der Beschreibung vom Erfassen beschreibender Details zum
Erfassen von Beziehungen verschoben. Wichtig sind dabei die Beziehungen, die man
außerhalb der traditionellen Bibliotheken findet. Als Beispiel werden die
Hinweise von Amazon auf ähnliche Bücher, für die ein Kunde sich interessieren
könnte, genannt. [Die Darstellung von bibframe ist entnommen aus:
http://www.loc.gov/bibframe/ -
Zugriff 2016-03-27.
Das Model besteht aus den folgenden Hauptklassen:
- "BIBFRAME Work" - entspricht der Entität Werk der
FRBR, enthält wohl auch Anforderungen der Entität Expression
- "BIBFRAME Instance" - entspricht der Entität Manifestation
der FRBR
- "BIBFRAME Authority" - identifiziert ein
Ding oder einen Begriff, der mit Werk oder Instanz verbunden ist
- "BIBFRAME Annotation" - ermöglicht eine
Erweiterung in der Beschreibung der drei vorhergehenden Hauptklassen also
zusätzliche Informationen
Für die Beschreibung von Ressourcen ist das
BIBFRAME-Vokabular entscheidend. Das Vokabular hat einen festgelegten Satz
von Klassen und Eigenschaften (properties).
Beispiel aus dem Text: Library
of Congress: Bibliographic framework as a web of data : Linked Data Model and
Supporting Services. - Washington, DC, November 21, 2012. -
http://www.loc.gov/marc/transition/pdf/marcld-report-11-21-2012.pdf --
Zugriff am 2016-03-27]
"Serializing the BIBFRAME model
There can be several serializations of the BIBFRAME Linked Data model. The
following XML serialization (of the RDF data model), while subject to
change, is provided as a concrete example. This example is designed to provide a
serialized encoding of a particular Work, its corresponding Instances and associated Authority
information. The Work in question is the ‘Functional Requirements for Bibliographic Records:
Final Report’.
The original BIBFRAME record associated with item is available here
http://lccn.loc.gov/2001433363.
Three Instances (one physical, one PDF, and one HTML web site)
along with the associated Authority information (subjects, authors, publishers, etc.)
are included in this example. The following example does not reflect a full MARC 21 to
BIBFRAME mapping. Links in the following examples are included to illustrate the use of
using URLs for defining BIBFRAME resources, the URLs themselves are not valid."
Die Beschreibung beginnt mit der
Entität Werk:
<!-- Work -->
<Report id =
"http://bibframe/work/frbr-report">
<title>Functional requirements for bibliographic records
:</title><titleRemainder>final report / IFLA
Study Group on the Functional Requirements for Bibliographic Records ; approved by the
Standing Committee of the IFLA Section on Cataloguing.</titleRemainder>
<creator resource = "http://bibframe/auth/org/ifla" />
<subject resource = "http://bibframe/auth/topic/cataloging"
/>
<subject resource = "http://bibframe/auth/topic/bibliography"
/><subject resource = "http://bibframe/auth/topic/frbr"
/>
<abstract>The purpose of this study is to delineate in
clearly defined terms the functions performed by the bibliographic
record with respect to various media, various applications, and various user
needs. The study is to cover the full range of functions for the
bibliographic record in its widest sense- i.e., a record that encompasses
not only descriptive elements, but access points (name, title,
subject, etc.), other 'organizing' elements (classification, etc.), and
annotations. </abstract><language>English</language>
<hasInstance
resource="http://bibframe/inst/frbr-1997-09-01:0" />
<hasInstance resource="http://bibframe/inst/frbr-1997-09-01:1"
/><hasInstance resource="http://bibframe/inst/frbr-1997-09-01:2"
/>
</Report>
Dieses Werk hat 3 Manifestationen = Instances: 1. Buch,
2. digitaler Text (PDF), 3. digitaler Text (html)
<!-- Instance -->
<HardcoverBook id="http://bibframe/inst/frbr-1997-09-01:0">
<date>1998</date>
<place resource=”http://bibframe/auth/geo/münchen” />
<publisher resource="http://bibframe/auth/org/k.g.saur" />
<isbn>359811382X</isbn>
</HardcoverBook>
<!-- Instance -->
<DigitalResource
id="http://bibframe/inst/frbr-1997-09-01:1">
<link>http://www.ifla.org/files/cataloguing/frbr/frbr_2008.pdf</link>
<format>application/pdf</format>
<date>1997-09-01</date>
<publisher
resource="http://bibframe/auth/org/ifla" />
</DigitalResource>
<!--
Instance -->
<DigitalResource
id="http://bibframe/inst/frbr-1997-09-01:2">
<link>http://archive.ifla.org/VII/s13/frbr/frbr_current_toc.htm</link>
<format>text/html</format>
<date>2007-12-26</date>
<publisher resource="http://bibframe/auth/org/ifla" />
</DigitalResource>
Das Werk hat 3 Themen: Topics
<!-- BIBFRAME Topic -->
<Topic
id="http://bibframe/auth/topic/frbr">
<label>FRBR (Conceptual model)</label>
<hasIDLink resource="http://id.loc.gov/authorities/subjects/
sh2007002541" />
</Topic><!-- BIBFRAME Topic
-->
<Topic id="http://bibframe/auth/topic/bibliography">
<label>Bibliography</label>
<generalSubdivision>Methodology</generalSubdivision>
<hasIDLink
resource=”http://id.loc.gov/authorities/subjects/sh85013838” />
</Topic>
<!-- BIBFRAME Topic -->
<Topic
id="http://bibframe/auth/topic/cataloging">
<label>Cataloging</label>
<hasIDLink resource=”http://id.loc.gov/authorities/subjects/sh85020816” />
</Topic>
Das Werk hat eine Beziehung zum
Verfasser: Organization
<!-- BIBFRAME Organization -->
<Organization id="http://bibframe/auth/org/ifla">
<label>IFLA Study Group on the Functional Requirements for
Bibliographic Records</label><link>http://www.ifla.org/</link>
<hasIDLink resource="http://id.loc.gov/authorities/names/nr98013265”
/>
</Organization>
Eine der Instances hat eine Beziehung zum Verleger:
Organization
<!-- BIBFRAME
Organization -->
<Organization id="http://bibframe/auth/org/k.g.saur">
<label>K.G. Saur</label>
<link>http://www.degruyter.com/</link>
<hasIDLink
resource="http://id.loc.gov/authorities/names/nr91037301” />
</Organization>
Die Beziehung zum Verleger ist der Verlagsort München:
Place
<!-- BIBFRAME
Place -->
<Place id=“http://bibframe/auth/geo/münchen”>
<label>Munich (Germany)</label>
<hasIDLink
resource=”http://id.loc.gov/authorities/names/n79059670” />
</Place>
"A high level RDF model reflecting the relationship between
the Work and the corresponding Instances as defined by this XML serialization is shown
in Figure 5.
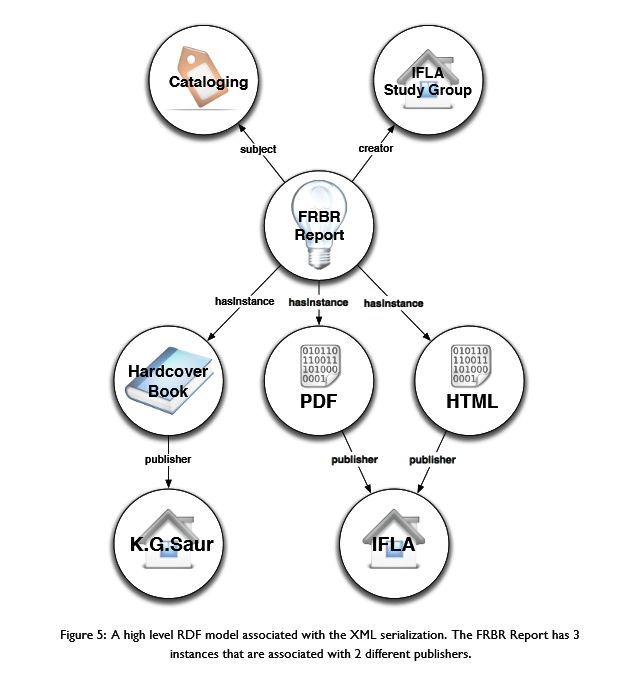
Die Instance Buch hat die folgende Signatur
(callNumber):
<!-- Holdings Annotation -->
<Holdings id="http://bibframe/annot/holdings/frbr-1997-09-01:0">
<annotates resource=”http://bibframe/inst/frbr-1997-09-01:0” />
<institution
resource=” http://bibframe/auth/org/ohio.university.alden” />
<callNumber>025.3 F979 1998</callNumber>
<access>circulating</access>
<status>available</status>
</Holdings>
Das Buch gehört folgender
Bibliothek: Beziehung zur Organisation
<!-- BIBFRAME Organization -->
<Organization
id="http://bibframe/auth/org/ohio.university.alden">
<label>Ohio University, Alden Library</label>
<city>Athens</city>
<state>OH</state>
<zip>45701</zip>
<link>http://www.library.ohiou.edu/</link>
<hasIDLink resource="http://id.loc.gov/authorities/names/n2003039990”
/>
</Organization>
Beispiel Ende s. a.a.O S. 16 - 20
Kritische Stimmen zu Bibframe
- FRBR kann damit (noch?) nicht voll erfüllt werden
- es werden teilweise andere Begriffe verwendet -
andere als in FRBR und RDA
Vorteil oder Nachteil:
Bibframe lässt zu, dass man auf die hierarchischen
Beziehungen von FRBR verzichtet zugunsten grafischer Darstellung, damit man die
Technik möglichst einfach machen kann. Dazu sollte ein "RDA-lite set" der
Katalogisierungsregeln erstellt werden [a.a.O. S. 15]
Seit 2014 werden in der LoC Aufnahmen nach Bibframe
getestet. Das nötige Standard-Vokabular wird zur Diskussion gestellt, soll 2015
revidiert werden und benutzt werden um zu testen, wie damit katalogisiert werden
kann. Diese Tests sollen den Bibframe Editor nutzen.
Während die LoC Bibframe auf RDF [Resource Description
Framework / W3C] aufgebaut hat, hat OCLC ein Modell für Linked Data mit Hilfe
von schema.org [http://schema.org --
Zugriff 2016-03-27] entwickelt:
Schema.org
Mit dem Vokabular von Schema.org können HTML-Seiten so
ausgezeichnet werden, dass die bekannten Suchmaschinen besser zugreifen können,
d.h. sie verstehen strukturierte Daten in bibliographischen Datenbanken und
können dadurch besser zugreifen. Zu den Suchmaschinen gehören Bing, Google,
Yahoo! und Yandex (russische Suchmachine). LoC und OCLC vergleichen zur Zeit die
beiden Initiativen und versuchen zusammen zu kommen:
s. Godby, Carol Jean, and Ray Denenberg: Common ground
: exploring compatibilities between the Linked Data Models of the Library of
Congress and OCLC. - Dublin, Ohio : Library of Congress and OCLC Research. 2015.
- URL:
http://www.oclc.org/content/dam/research/publications/2015/oclcresearch-loc-linked-data-2015-a4.pdf
- Zugriff 2016-03-26