
mailto: payer@hdm-stuttgart.de
Zitierweise / cite as:
Payer, Margarete <1942 - > ; Payer, Alois <1944 - >: Inhaltliche Strukturierung von Ressourcen : eine Einführung in XML. -- 10. XPath. -- Fassung vom 2002-10-29. -- URL: http://www.payer.de/xml/xml10.htm. -- [Stichwort].
Erstmals publiziert:
Überarbeitungen:
Anlass: Lehrveranstaltung an der HdM Stuttgart, SS 2002
Unterrichtsmaterialien (gemäß § 46 (1) UrhG)
©opyright: Dieser Text steht der Allgemeinheit zur Verfügung. Eine Verwertung in Publikationen, die über übliche Zitate hinausgeht, bedarf der ausdrücklichen Genehmigung der Herausgeberin.
Dieser Teil ist ein Kapitel von:
Payer, Margarete <1942 - > ; Payer, Alois <1944 - >: Inhaltliche Strukturierung von Ressourcen : eine Einführung in XML. -- 0. Übersicht. -- URL: http://www.payer.de/xml/xml00.htm
Dieser Text ist Teil der Abteilung Informationswesen, Bibliothekswesen, Dokumentationswesen von Tüpfli's Global Village Library.
Zum Zeitpunkt der Abfassung dieses Kapitels gilt XPath Version 1.0. -- W3C Recommendation 16 November 1999. Die jeweils neueste Version findet man unter URL: http://www.w3.org/TR/xpath. -- Zugriff am 2002-04-30.
Deutsche Übersetzung: XML Path Language (XPath). -- Version 1.0. -- Deutsche, kommentierte Übersetzung 26. Februar 2002. -- Übersetzer: Oliver Becker. -- URL: http://www.edition-w3c.de/TR/xpath. -- Zugriff am 2002-11-19
In HTML kann man Teile eines Dokuments nur dann adressieren, wenn dort eine Textmarke gesetzt ist. Zweck von XPath ist es, Teile eines XML-Dokuments zu adressieren ohne dass dort ein Identifikator (eine Textmarke) gesetzt sein muss. Es geht also darum, dass man (mindestens) wie im täglichen Leben zitieren kann - z.B. Kapitel 5, Absatz 3; Abbildung 130; Anhang 4, Tabelle 2 - ohne dass die für das Dokument verantwortlichen vorhersehen müssen, auf was alles Nutzer gezielt zugreifen wollen.
XPath wird zur Zeit innerhalb von von XPointer (siehe Kapitel 8) und XSLT (siehe Kapitel 12) verwendet.
Viele Lokalisierungen mittels von XPath lassen sich auf zweierlei Art ausdrücken:
Lokalisierung geschieht mittels eines Lokalisierungspfades (location path), der wiederum aus Lokalisierungsschritten (location steps) zusammengesetzt ist.
Ein Lokalisierungspfad (location path) von XML kann sein:
Ein relativer Lokalisierungspfad besteht aus einem oder mehreren Lokalisierungsschritten (location steps), die durch den Schrägstrich / getrennt sind. Jeder Lokalisierungsschritt wählt eine Anzahl von Knoten inbezug auf den jeweiligen Kontextknoten. Der erste Lokalisierungsschritt bestimmt eine Anzahl von Knoten inbezug auf einen Kontextknoten. Jeder Knoten der so bestimmten Knoten ist Kontextknoten für den Nächsten Lokalisierungsschritt. Usw. usw.
child::Kapitel/child::Abschnitt bzw. Kapitel/Abschnitt wählt z.B. alle Elemente Abschnitt aus, die Kinder von Elementen Kapitel sind, die Kinder des (relativen) Kontexktknoten sind
Ein absoluter Lokalisierungspfad besteht aus dem Schrägstrich / als Bezeichnung für den Wurzelknoten (root node), gefolgt von einem relativen Lokalisierungspfad
/child::Monographie/child::Kapitel/child::Abschnitt bzw. /Monographie/Kapitel/Abschnitt wählt z.B. alle Elemente Abschnitt die Kinder von Elementen Kapitel sind, die Kinder des obersten Elements Monographie sind
Ein Lokalisierungsschritt besteht aus bis zu drei Teilen:
Achsenbezeichnung und node test werden durch zwei Doppelpunkte :: voneinenader getrennt, eventuelle Prädikate folgen auf den node test, wobei jedes Prädikat in eckigen Klammern [] steht.
|
Achsenbezeichnung::node test [Prädikat][Prädikat] z.B.: child::Abschnitt[position()=1] Hier ist
|
Im Folgenden werden die Bestandteile eines Lokalisierungsschritts weiter erklärt.
Der Knotentest (node test) wählt anhand eines Musters einen oder mehrere Knoten (Knotenmenge) innerhalb der betreffenden Achse aus. Stimmt kein Knoten mit dem Kriterium des Knotentests überein, bleibt die Auswahl leer.
Knotentest kann sein:
Knotentests können auch mehrere Alternativen enthalten, die durch den Operator | getrennt werden:
Als Achsen (axes) werden drei unterschiedliche Typen verwendet. Die drei Typen sind so unterschiedlich, dass es zu den großen Mängeln von XPath gehört, alle drei als Achsen zu bezeichnen:
attribute: für Attribut
namespace: für namespace
alle anderen Achsen drücken Beziehungen (Verwandtschaftsbeziehungen, Identitätsbeziehungen und Folgebeziehungen) zwischen Elementen aus
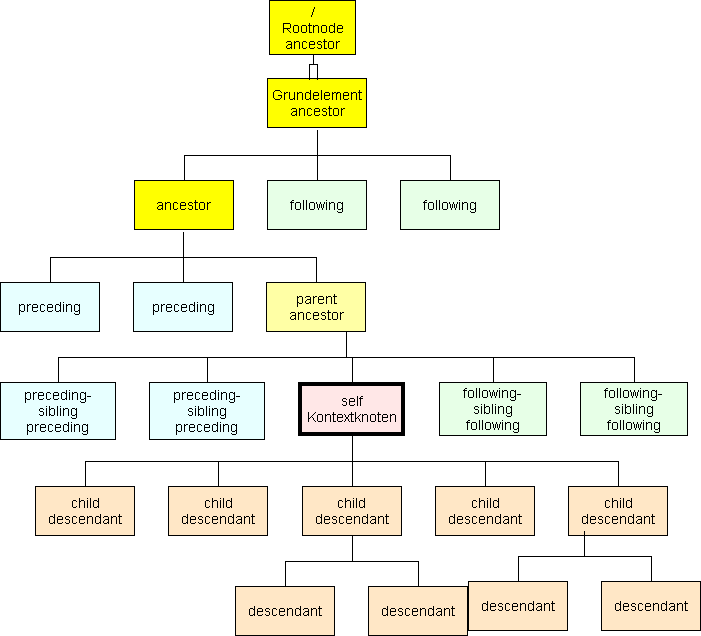
Abb.: Elementachsen
Die Achsen
zusammen, teilen alle Elemente der Ressource vom jeweiligen Kontextknoten ausgehend auf. Bezogen auf einen einzigen Kontextknoten überlappen sie sich nie.
/ = Rootelement = Elternelement zum Grundelement (Dokumentenelement)
child:: die Kinder (unmittelbaren Unterknoten) des Kontextknoten
Da child:: dieStandardachse ist, kann diese Bezeichnung immer weggelassen werden: Kapitel/Abschnitt ist gleichwertig mit child::Kapitel/child::Abschnitt
| Unabgekürzte Syntax | Abgekürzte Syntax | Erklärung |
|---|---|---|
| child::Kapitel | Kapitel | Wählt alle Elementknoten Kapitel aus, die Kinder des Kontextknotens sind. |
| child::* | * | Wählt alle Elementknoten aus, die Kinder des Kontextknotens sind |
| child::text() | text() | Wählt alle Textknoten aus, die Kinder des Kontextknotens sind |
| child::node() | node() | Wählt alle Kinder des Kontextknotens aus |
| child::Kapitel/descendant::Abschnitt | Kapitel//Abschnitt | Wählt alle Elemente Abschnitt aus, die Nachkommen der Elemente Kapitel sind, welche Kinder des Kontextknotens sind |
| child::*/child::Abschnitt | */Abschnitt | Wählt alle Elemente Abschnitt aus, die Großkinder (Enkel) des Kontextknotens sind |
| child::Abschnitt[position()=1] | Abschnitt[1] | Wählt das erste Element Abschnitt aus, das Kind des Kontextknotens ist |
| child::Abschnitt[position()=last()] | Abschnitt[last()] | Wählt das letzte Element Abschnitt aus, das Kind des Kontextknotens ist |
| child::Abschnitt[position()=last()-1] | Abschnitt[last()-1] | Wählt das vorletzte Element Abschnitt aus, das Kind des Kontextknotens ist |
| child::Abschnitt[position()>1] | Abschnitt[>1] | Wählt alle Elemente Abschnitt aus, die Großkinder (Enkel) des Kontextknotens sind, mit Ausnahme des ersten |
| /child::Monographie/child::Kapitel[position()=5]/child::Abschnitt[position()=2] | /Monographie/Kapitel[5]/Abschnitt[2] | Wählt das zweite Element Abschnitt des fünften Elements Kapitel des obersten Elements Monographie aus; d.h. den zweiten Abschnitt des fünften Kapitels der Monographie. |
| child::Abschnitt[attribute::Sicherheit="topsecret"] | Abschnitt[@Sicherheit="topsecret"] | Wählt alle Elemente Abschnitt aus, die Kinder des Kontextknoten sind und im Attribut Sicherheit den Wert topsecret haben |
| child::Abschnitt[attribute::Sicherheit="topsecret"][position()=5] | Abschnitt[@Sicherheit="topsecret"][5] | Wählt das fünfte Elemente Abschnitt aus, das Kind des Kontextknoten ist und im Attribut Sicherheit den Wert topsecret hat |
| child::Abschnitt[position()=5][attribute::Sicherheit="topsecret"] | Abschnitt[5][@Sicherheit="topsecret"] | Wählt das fünfte Elemente Abschnitt aus, das Kind des Kontextknoten ist, wenn es im Attribut Sicherheit den Wert topsecret hat |
| child::Kapitel[child::Kapitelueberschrift] | Kapitel[Kapitelueberschrift] | Wählt die Elemente Kapitel aus, die Kinder des Kontextknoten sind und als Kinder ein oder mehrere Elemente Kapitelueberschrift haben |
| child::Kapitel[child::Kapitelueberschrift="Einleitung"] | Kapitel[Kapitelueberschrift="Einleitung"] | Wählt die Elemente Kapitel aus, die Kinder des Kontextknoten sind und als Kinder ein oder mehrere Elemente Kapitelueberschrift haben, die Einleitung heißen. |
| child::*[self::Kapitel or self::Anhang] | Wählt alle Elemente Kapitel und Anhang aus, die Kinder des Kontextknotens sind | |
| child::*[self::Kapitel or self::Anhang][position()=last()] | Wählt das letzte Element Kapitel oder Anhang, das Kind des Kontextknoten ist. |
descendant:: die Nachkommen des Kontextknoten. Ein Nachkomme ist ein Kind, Kindeskind, Kindeskindkind usw. attribute und namespace gelten nicht als Nachkommen
|
descendant::Abschnitt |
wählt die Elemente Abschnitt aus, die Nachkommen des Kontextknoten sind | |
| /descendant::Abschnitt | //Abschnitt | wählt alle Elemente Abschnitt aus, die Nachkommen des Rootelements sind, d.h. alle Elemnente Abschnitt, die zum gleichen Dokument gehören wie der Kontextknoten |
| /descendant::geordneteListe/child::Listenelement | //geordneteListe/Listenelement | wählt alle Elemente Listenelement aus, die Kinder eines Elements geordneteListe sind und zum selben Dokument wie der Kontextknoten gehören |
| /descendant::Abbildung[position()=42] | /descendant::Abbildung[42] | wählt das 42. Element Abbildung im Dokument aus |
parent:: Der Elternknoten des Kontextknotens, falls vorhanden
.. ist die Abkürzung für parent::node(). Z.B. ../Kapitelueberschrift ist gleichbedeutend mit parent::node()/child::Kapitelueberschrift und wählt alle Elemente Kapitelüberschrift aus, die Kinder des Elternknotens des Kontextknotens sind.
ancestor:: Vorfahren des Kontextknotens. Vorfahren sind Elter, Elterelter, Elterletrelter usw. bis inklusive Wurzelknoten, soweit vorhanden
Beispiel:
ancestor::Teil wählt alle Elemente Teil aus, die Vorfahren des Kontextknoten sind.
following-sibling:: nachfolgende Geschwister, d.h. nachfolgende Elemente mit dem gleichen Elter wie Kontexknoten. Ist der Kontexknoten attribute oder namespace, ist following-sibling leer
Beispiel:
following-sibling::Kapitel[position()=1] wählt das nächste Geschwister-Element Kapitel nach dem Kontextknoten aus.
preceding-sibling:: vorausgehende Geschwister, d.h. vorausgehende Elemente mit dem gleichen Elter wie Kontexknoten. Ist der Kontexknoten attribute oder namespace, ist following-sibling leer
Beispiel:
preceding-sibling::Kapitel[position()=1] wählt das nächste Geschwister-Element Kapitel aus, das dem Kontextelement vorausgeht.
following:: Elemente nach dem Kontextknoten mit Ausnahme von seinen Nachkommen (child bzw. descendant) sowie attribute und namespace.
preceding:: Elemente vor dem Kontextknoten mit Ausnahme von seinen Vorfahren (parent bzw. ancestort) sowie attribute und namespace.
self:: der Kontextknoten selbst
. ist die Abkürzung für
self::node(). Diese Abkürzung ist besonders nützlich in Verbindung mit //.
So ist z.B. .//Abschnitt gleichbedeutend mit
Beispiel:
self::Abschnitt wählt den Kontexknoten aus, wenn er ein Element Abschnitt ist, andernfalls wählt es nichts aus.
descendant-or-self:: der Kontextknoten und seine Nachkommen (child bzw. descendant)
/descendant-or-self::node()/ kann zu // abgekürzt werden
Beispiel:
descendant-or-self::Abschnitt wählt die Elemente Abschnitt aus, die Nachkommen des Kontextknoten sind
/dexcendant-or-self::node()/child::Abschnitt ist gleichbedeutend mit //Abschnitt wählt jedes Element Abschnitt aus, das im Dokument vorkommt. (Sollte das oberste Element Abschnitt sein, wird auch dieses ausgewählt, da es nach der Konvention ein Kind des Wurzelelements ist).
Teil//Abschnitt ist gleichbedeutend mit Teil/descendant-or-self::node()/child::Abschnitt. Es wählt alle Elemente Abschnitt aus, die Kinder eines Nachkommen eines Elements Teil sind.
Achtung! //Abschnitt[1] ist nicht gleichbedeutend mit /descendant::Abschnitt[1]:
ancestor-or-self:: der Kontextknoten und seine Vorfahren (parent bzw. ancestor) inklusive Wurzelknoten.
Beispiel:
ancestor-or-self::Teil wählt die Elemente Teil aus, die Vorfahren des Kontextknoten sind, sowie den Kontextknoten selbst, falls dieser ein Element Teil ist.
attribute:: Attribute des Kontextknotens, falls dieser ein Element ist.
attribute:: kann mit @ abgekürzt werden. Z.B. sind Abschnitt[@type="warning"] und child::Abschnitt[attribute::type="warning"] gleichbedeutend
Beispiele:
attribute::Name bzw @Name wählt das Attribut Name des Kontextknoten aus
attribute::* bzw. @* wählt alle Attribute des Kontextknotens aus.
namespace:: Namespace des Kontextknotens, falls der Kontextknoten ein Element ist.
Prädikate dienen der weiteren Einschränkung derauf der betreffenden Achse durch den Knotentest ausgewählten Elemente bzw. Knoten. Prädikate stehen in eckigen Klammern.
Beispiele für Prädikate sind:
Es können mehrere Prädikate aneinandergereiht werden. Ihre Reihenfolge ist relevant, da sie von links nach rechts abgearbeitet werden.
Beispiele für aneinandergereihte Prädikate:
XPath definiert lange und umständlich und ohne brauchbare Beispiele Funktionen und Ausdrücke. Die in den vorhergehenden Abschnitten in Beispielen gegebenen Funktionen und Ausdrücke sind vermutlich im Allgemeinen ausreichend.
Ausdrücke werden gebildet durch
Funktionen
Es steht zu befürchten, dass all dies zwar theoretisch sehr wertvoll ist, aber der konsequenten Durchsetzung von XPath eher hinderlich ist.
Zu Kapitel 11: XPointer