mailto: payer@hbi-stuttgart.de
Zitierweise / cite as:
Payer, Margarete <1942 -- >: Computervermittelte Kommunikation. -- Kapitel 12: OSI-Schicht 6: Presentation Layer -- Datendarstellungsschicht. -- Teil 2: SGML und XML. -- Fassung vom 2001-01-21. -- URL: http://www.payer.de/cmc/cmcs1202.htm. -- [Stichwort].
Erstmals publiziert: 1995
▄berarbeitungen: 23. Juni 1997; 21.6.1999 [grundlegende Neubearbeitung und Erweiterung]; 2001-01-21 [Kleine Verbesserungen]
Anlass: Lehrveranstaltungen an der HBI Stuttgart
®opyright: Dieser Text steht der Allgemeinheit zur Verf³gung. Eine Verwertung in Publikationen, die ³ber ³bliche Zitate hinausgeht, bedarf der ausdr³cklichen Genehmigung der Verfasserin.
Zur Inhalts³bersicht von Margarete Payer: Computervermittelte Kommunikation.
Zu den wichtigsten "Formaten" f³r den Austausch von Daten geh÷ren SGML (Standard Generalized Markup Language) und XML (Extensible Markup Language).
| 1. | Gedankliche Konzeption | als solche nicht darstellbar |
|---|---|---|
| 2. | Computer-Fassung von Werk | als solche nicht darstellbar |
| 3. | Computerfassung von Ausformung | als solche nicht darstellbar |
| 4. | Computerfassung der Manifestation | darstellbar |
| 5. | Physische Darstellung des Einzelexemplars | benutzbar |
| Werk | Statistische Datenbanken des Bundes und der Lõnder |
|||||
|---|---|---|---|---|---|---|
| Ausformungen | Statistisches Jahrbuch der BRD | Lõnderberichte (auslõndische Staaten) | Atlas | Agrarstatistik usw. | ||
| Manifestationen | Druckausgabe | CD-ROM | On-line | |||
| Einzelexemplare | gedruckte B³cher | physische CD-ROMs |
On-line Sites | ..... | ||
| Werk und seine Derivate | Computer-Fassung | Physische Darstellung |
|---|---|---|
| Werk (work, abstraction) | SGML | |
| Ausformung (expression, abstraction) | SGML, XML, [HTML (semantische Tags)] | |
| Manifestation (manifestation, rendition, Ausgabe) | SGML-DTD, XML-DTD, HTML (Style-Tags), PostScript, Textverarbeitungsformate, Style sheets ... | |
| Einzelexemplar (item) | Verschiedene Medien: Hardcopy, Braille, Bildschirmdarstellung, CD-Rom, Audio, Video .... |
SGML -- Standard Generalized Markup Language ist eine Dokument-Definier-Sprache, die den Austausch von Informationen beliebiger Komplexitõt unabhõngig von herstellerspezifischer Soft- und Hardware erm÷glichen soll. |
SGML ist internationaler ISO-Standard:
ISO 8879 (1986): Information processing -- Text and office systems -- Standard Generalized Markup Language (SGML)
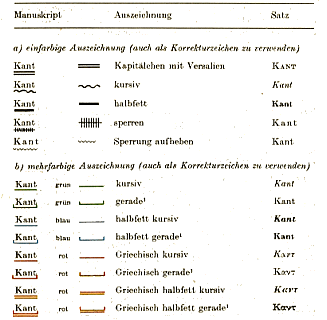
Markup-Languages sind keine neue Erfindung: in der Form von Satzanweisungen waren sie ein unentbehrliches Hilfsmittel f³r Verfasser und Lektoren, um Schriftsetzern ihre W³nsche mitzuteilen, wie das Manuskript (die "Ausformung" des Werkes) in eine "Manifestation" umgesetzt werden soll. Die folgenden Abbildungen zeigen einen Ausriss einer solchen Markup-Language, wie sie in den 60er und 70er-Jahren des 20. Jahrhunderts in Deutschland gebrõuchlich war:
| Markup | Beispiel |
|---|---|
|
|
|
Abb.: "Klassische" Markup-Language: Markup f³r Buchsatz
Quelle der Abb.: Satzanweisungen und Korrekturvorschriften : mit ausf³hrlicher Beispielsammlung / hrsg. von der Dudenredaktion und der Dudensetzerei. -- Mannheim : Bibliographisches Institut, ®1969. -- 187 S. : Ill. -- (Duden-Taschenb³cher ; 5/5a). -- [Ein "klassisches" Regelwerk einer Markup-Language f³r die Epoche der traditionellen Buchproduktion]
F³r den anglo-amerikanischen Raum sind die Regeln einer dieser klassischen Markup-Languages (neben vielem anderen) immer noch enthalten in:
The Chicago Manual of Style. -- 14. ed. -- Chicago [u.a.] : Univ. of Chicago Press, ®1993. -- 921 S. : Ill. -- ISBN 0226103897. -- {Wenn Sie HIER klicken, k÷nnen Sie dieses Buch bei amazon.de bestellen}
Ausgangspunkt zu SGML in ihrer jetzigen Form war der Paradigmawechsel vom Konzept des Specific Coding (Procedural Markup) zum Konzept des Generic Coding (Descriptive Markup).
Vermutlich geht die Anregung zu diesem Paradigmenwechsel auf William Tunnicliffe zur³ck, der 1967 bei einer Sitzung des Canadian Government Printing Office vorschlug, den Informationsgehalt eines Dokumentes von seinem Format zu trennen. Diese und andere Anregungen f³hrten zur Gr³ndung des Generic Coding Projekt innerhalb des Composition Committe der Graphic Communications Association (GCA). In diesem Projekt wurde das GenCode(R)-Konzept entwickelt: man erkannte, dass verschiedene Arten von Dokumenten verschiedene Codes ben÷tigen und, dass man kleinere Dokumente als Elemente in gr÷▀ere Dokumente einbinden k÷nnte.
Es zeigte sich bald, dass der Versuch, ein Generic Coding f³r alle Dokumententypen zu entwerfen, daran scheitern w³rde, dass es zu viele verschiedene Dokumententypen mit zu vielen unterschiedlichen Arten von Elementen gibt. Die L÷sung fand man darin, dass man SGML nicht als eine Gesamtheit von standardisierten Codes entwarf, sondern als eine Art Programmiersprache, mit der man eine Dokumenten-Typ-Definition (document type definition) (DTD) erstellen konnte. Die DTD kann die Elemente usw. definieren, die man f³r ein Dokument oder eine Gruppe õhnlicher Dokumente ben÷tigt. Das Vorbild daf³r lieferten Programmiersprachen, die es erlauben "primitives" zu definieren, Grundoperationen, die man in einem header file zusammenstellen kann, um Befehle zu definieren, die das Programm dann benutzt.
1980 wurde ein erster Entwurf von SGML ver÷ffentlicht. Im Oktober 1985 wurde ein Draft International Standard ver÷ffentlicht und vom Office of Official Publications of the European Community angenommen. 1986 wurde der endg³ltige Text, der am CERN ausgearbeitet wurde, von ISO als Standard akzeptiert und in Rekordzeit ver÷ffentlicht.
Als im WWW (World Wide Web) immer mehr proprietõre HTML-Erweiterungen auftauchten (vor allem von Netscape und Microsoft), reagierte das World Wide Web Consortium unter Leitung von Tim Berners-Lee, dem Erfinder von HTML, ab ca. 1996:
XML 1.0 wurde offiziell am 10.2.1998 ver÷ffentlicht.
Jedes Dokument besteht aus:
SGML ist eine Sprache zum Definieren des Markup
SGML ist eine Computer-Sprache: ein Computerprogramm -- ein validating SGML parser -- liest die Definitionen, lernt die daraus folgenden Regeln und wendet sie auf das Dokument an.
Die folgende Abbildung fasst an einem Beispiel zeitgemõ▀es SGML- (bzw. XML-)gest³tztes Publizieren zusammen:
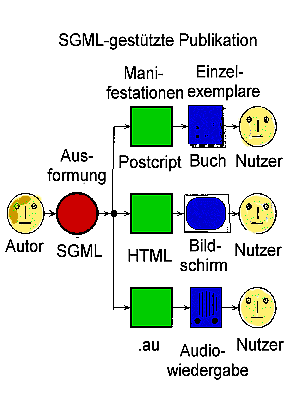
Abb.: SGML-gest³tztes Publizieren
Im hier schematisch wiedergegebenen Beispiel wird die Ausformung eines Werkes (SGML) in verschiedenen Manifestationen publiziert:
als Druckanweisung (Postscript)
als HTML-File
als Audio-File (.au)
Diese Manifestationen werden als Einzelexemplare realisiert:
als gedruckte B³cher
als Bildschirmdarstellungen bzw. Ausdrucke von WWW-Pages
als Lautwiedergabe von Audio-Files (z.B. von Kassette, CD-ROM, im Radio, im WWW usw.)
Ein SGML profile ist eine Anzahl von Regeln, die auf verschiedene SGML Document types anwendbar sind. Ein profile kann
Das erste ÷ffentlich definierte profile von SGML ist XML. XML ist f³r das WWW optimiert.
XML-Dokumente k÷nnen sein
XML ist ein stark vereinfachtes SGML (SGML minus minus (--)), das SGML f³r das WWW ebenso leicht anwendbar machen soll, wie HTML eine bestimmte DTD von SGML populõr gemacht hat.
| SGML -- Standard Generalized Markup Language | Allgemeine Markup-Language f³r alle Arten von Anwendungen: von der Transkription sumerischer Tontõfelchen bis zur technischen Dokumentation von Weltraumfahrzeugen, von Patientendaten bis zu musikalischen Notationen |
|---|---|
| XML -- Extensible Markup Language | Vereinfachte Fassung von SGML. XML ist SGML--, nicht HTML++ |
| HTML -- HyperText Markup Language | Ein document type, der mittels von SGML definiert ist |
XML ist ein Projekt des WWW-Konsortium (W3C).
XML befreit das WWW von:
F³r die Nutzung von XML-Dokumenten sind spezielle Browser n÷tig. Solche sind teilweise schon erhõltlich, wirklich gute werden aber wohl noch einige Zeit auf sich warten lassen.
Die XML declaration wird oft weggelassen, wenn man annehmen kann, dass sowohl das sendende als auch das empfangende System die default syntax (reference concrete syntax) benutzen.
Konvention im Folgenden: { }: der Wert f³r die zwischen den geschwungenen Klammern stehende Variable ist einzusetzen (die geschwungenen Klammern sind dann wegzulassen!).
Achtung: XML ist case sensitive, d.h. Gro▀- und Kleinschreibung f³r XML-Sprachbestandteile d³rfen nicht verõndert werden und die gewõhlte Schreibung variabler Elemente muss beibehalten werden! (Also: !ELEMENT muss mit Gro▀buchstaben geschrieben werden!)
| Option | Syntax | Beispiel |
|---|---|---|
| Nur XML-Version | <?xml version="{Versionsnummer}"?> | <?xml version="1.0"?> |
| XML-Version + Zeichenkodierung (Standard:: UTF-8) | <?xml version="{Versionsnummer}" encoding="{Kodierung}"?> | <?xml version="1.0" encoding="UTF-8"?> |
| XML-Version + Standalone document declaration | <?xml version="{Versionsnummer}" standalone="{yes/no}"?> | <?xml version="1.0" standalone="no"?> |
Erklõrung:
Innerhalb des Dokuments k÷nnen Sonderzeichen dann auf zwei Arten bezeichnet werden
| Methode | Syntax | Beispiele |
|---|---|---|
| character reference | &#{binõrer Wert}; &#x{hexadezimaler Wert}; |
¡ [= ¡
] ¡ [= ¡ ] |
| Definition von Sonderzeichen (sog. predefined entity references) (soweit vorhanden) | &{Sonderzeichendefinition}; |
|
Die document type definition (DTD) definiert die Elemente und anderen Konstrukte, die f³r ein spezifisches Dokument oder eine Gruppe von Dokumenten ben÷tigt werden.
Die DTD und jeder ihrer Teile hat die allgemeine Syntax:
| <! {Inhalt} > |
Eine DTD kann sein:
Es gibt folgende Optionen:
| Option | Syntax | Beispiel |
|---|---|---|
| Hinweis auf eine dokumentexterne DTD | <!DOCTYPE {Name der DTD} SYSTEM "{URL der DTD}"> | <!DOCTYPE Dissertation SYSTEM "http://www.payer.de/dissertation.dtd"> |
| Hinweis auf eine dokumentexterne ÷ffentliche DTD | <!DOCTYPE {Name der DTD} PUBLIC "{ųffentliche Bezeichnung der DTD}" "{URL der DTD}"> | <!DOCTYPE Dissertation PUBLIC "-//AKADEMISCH//DTD DISS//EN" "http://www.ddb.de/dtd/diss.dtd"> |
| DTD (dokumentenintern) | <!DOCTYPE {Name der DTD} [ <!{DTD}> (Syntax s. unten!) ]> |
<!DOCTYPE Dissertation [ <!ELEMENT Dissertation (Titelblatt, Kapitel+, Zusammenfassung, Literaturverz, Lebenslauf)> <!ELEMENT Titelblatt (Titel, Autor, Lebensdaten, WissInst, Jahr, ...)> <!ELEMENT (Titel | Autor | Lebensdaten | WissInst | Jahr | ...) (#PCDATA)> <!ELEMENT Kapitel (....)> ... ]> |
| gemischt: Hinweis auf dokumentenexterne DTD mit Sonderregelungen f³r das vorliegende Dokument | <!DOCTYPE {Name der DTD} SYSTEM "{URL der DTD}" [ <!{Sonderregelungen}> ]> |
<!DOCTYPE Dissertation PUBLIC "-//AKADEMISCH//DTD
DISS//EN" "http://www.ddb.de/dtd/diss.dtd" [ <!ELEMENT Lebensdaten EMPTY> ]> |
Eine DTD hat folgende Struktur:
| Syntax | Beispiel |
|---|---|
| <!DOCTYPE {Name der DTD} [ <!ELEMENT {Elementname des obersten Elements}{Elementinhalt}> <!ELEMENT {Elementname}{Elementinhalt}> ... ]> |
<!DOCTYPE Dissertation [ <!ELEMENT Dissertation (Titelblatt, Kapitel+, Zusammenfassung, Literaturverz, Lebenslauf)> <!ELEMENT Titelblatt (Titel, Autor, Lebensdaten, WissInst, Jahr, ...)> <!ELEMENT (Titel | Autor | Lebensdaten | WissInst | Jahr | ...) (#PCDATA)> <!ELEMENT Kapitel (....)> ... ]> |
Jede DTD hat genau ein oberstes Element, dessen Elementinhalt bestimmt, was alles Inhalt des Dokuments sein kann: z.B. andere Elemente. F³r die Elemente kann man Meta-data in der Form von Attributen festlegen.
Die Elemente werden in element declarations definiert. Element declarations haben zwei Aufgaben:
| Syntax | Beispiel |
|---|---|
| <!ELEMENT Element_name Content_specification> | <!ELEMENT Kapitel (KapTitel, (Para | Zwischentit)+) >
Erklõrung:
= Definition des Elementes Kapitel:
Die Anweisung f³r XML-Software lautet also: "Kapitel ist der Name eines Elementes, welches aus einem KapTitel sowie ein oder mehreren Para oder Zwischentit besteht." |
Jedes Subelement muss ebenso definiert werden. In unserem Beispiel m³ssen die Inhalte (contents) der Unterelemente (subelements) KapTitel, Para, Zwischentit definiert werden. Wenn alle die gleiche Content_specification haben, kann man dies in einer einzigen element definition tun:
<!ELEMENT (KapTitel | Para | Zwischentit) (#PCDATA)>
PCDATA ist ein reservierter Name, der definiert, dass die betreffenden Elemente keine eigenen Unterelemente haben, sondern nur Zeichen enthalten, die zum Inhalt des Dokumentes geh÷ren. PCDATA = parsed character data.
Mit diesen element definitions und den zuvor gegebenen predefined entity references k÷nnte man z.B. folgendes Dokument erstellen:
|
<Kapitel> <KapTit>Katzenweisheit</KapTit>
<Zwischentit>Tüpfli zum Beispiel</Zwischentit>
</Kapitel> |
Man kann Elementen Attribute zuordnen. So k÷nnte man z.B. dem Element Para zwei Stufen der Zugõnglichkeit zuordnen: topsecret und public:
| <!ATTLIST para secrecy (topsec | public) "public"> |
"public" definiert public als default value: Alle Paragraphen, die nicht ausdr³cklich als topsecret gekennzeichnet werden, sind public.
Unser Beispiel k÷nnte dann z.B. so aussehen:
|
<Kapitel> <KapTit>Katzenweisheit</KapTit>
<Zwischentit>Tüpfli zum Beispiel</Zwischentit>
</Kapitel> |
In diesem Falle w³rde die Abstammung T³pflis nur berechtigten Geheimnistrõgern zugõnglich gemacht.
Im Folgenden wird das mit diesem Beispiel Illustrierte systematisch dargestellt.
| Syntax | Beispiel |
|---|---|
| <!{keyword} {parameter} {associated_parameters}> | <!ELEMENT Kapitel (KapTitel, (Para | Zwischentit)+) > |
Erklõrung:
keyword: Die wichtigsten Keywords sind:
| keyword | Funktion | Beispiel |
|---|---|---|
| DOCTYPE | ordnet einer Gruppe von Declarations einen Namen zu, z.B. Namen des ganzen Dokuments | <!DOCTYPE DISSERTATION [ <!ELEMENT Titelblatt (Titel, Autor, Lebensdaten, WissInst, Jahr, ...)> <!ELEMENT (Titel | Autor| Lebensdaten | WissInst | Jahr| ...) (#PCDATA)> <!ELEMENT Kapitel (....)> ... ]> |
| ELEMENT | definiert ein Element innerhalb der logischen Struktur eines Dokumentes. associated_parameters gibt hier die m÷glichen Inhalte dieses Elementes an (content model) | <!ELEMENT Kapitel (KapTitel, (Para | Zwischentit)+) > <!ELEMENT (KapTitel | Para | Zwischentit) (#PCDATA)> |
| ATTLIST | Zuordnung von Attributen zu einem Element | <!ATTLIST para secrecy (topsec | public) "public"> |
| ENTITY | erm÷glicht, eine Kurzform f³r etwas Lõngeres einzugeben, oder auf ein externes File zu verweisen | <!ENTITY T³ "T³bingen, Univ., Diss.,"> |
| NOTATION | verbindet den ersten Parameter, der Non-XML-data bezeichnet mit dem zweiten Parameter, der dem System angibt, wie so Bezeichnetes zu behandeln ist: z.B: MIDI f³r MIDI-Files, CGM f³r Graphik u.õ. | <!NOTATION MathText SYSTEM "/usr/bin/tex" > ( = mathematischer Text ist zu bearbeiten mit einem Sub-Programm, das als usr/bin/tex gespeichert ist) |
| Parameter ist immer der Name, der f³r das betreffende Markup verwendet werden soll | <!DOCTYPE DISSERTATION ... > <!ELEMENT Kapitel ...> <!ATTLIST para secrecy ...> |
associated parameters:
Innerhalb von associated_parameter (und teilweise innerhalb der parameter) k÷nnen folgende Indikatoren und Verkn³pfungszeichen vorkommen:
| Indikator / Verkn³pfungszeichen | Bedeutung | Erklõrung | Beispiel |
|---|---|---|---|
|
kein Indikator |
das betreffende Element usw. muss genau einmal vorkommen | <!ELEMENT BibliogrBeschreibung (Titelangabe, Verfasserangabe, Ausgabebezeichnung?, Erscheinungsvermerk, Kollationsvermerk, Gesamttitel?, URN?)> | |
|
( ) |
Gruppe | zwischen der Parenthese steht eine Abfolge, eine Gruppe oder eine Reihe von Alternativen | <!ELEMENT Titelblatt (Titel, Autor, Lebensdaten, WissInst, Jahr,
...)> <!ELEMENT (Titel | Autor | Lebensdaten | WissInst | Jahr | ...) (#PCDATA)> <!ATTLIST para secrecy (topsec | public) "public"> |
|
|
optional | das betreffende Element usw. kann
vorkommen |
<!ELEMENT BibliogrBeschreibung (Titelangabe, Verfasserangabe, Ausgabebezeichnung?, Erscheinungsvermerk, Kollationsvermerk, Gesamttitel?, URN?)> |
|
optional und wiederholbar | das betreffende Element usw. kann
vorkommen |
<!ELEMENT authgrp (author|corpauth|aff)* > |
|
notwendig und wiederholbar | das betreffende Element usw. muss
vorkommen |
<!ELEMENT Kapitel (KapTitel, (Para | Zwischentit)+) > |
|
aufeinanderfolgend |
|
|
|
oder (OR) | mindestens eines der so verkn³pften Elemente usw. muss vorkommen |
Comment declarations f³r Anmerkungen und Erklõrungen des Produzenten des XML-Dokumentes, die vom System nicht beachtet werden sollen, haben folgende Syntax:
| Syntax | Beispiel |
|---|---|
| <!-- {Text der Anmerkung} --> | <!-- Dies ist eine DTD f³r deutschsprachige Dissertationen --> |
Syntax:
| Syntax | Beispiel |
|---|---|
| <!ELEMENT Element_name Content_specification> | <!ELEMENT Kapitel (KapTitel, (Para | Zwischentit)+) > <!ELEMENT (KapTitel | Para | Zwischentit) (#PCDATA)> |
Erklõrung:
| Content_specification | Erklõrung | Beispiel |
|---|---|---|
| element content | eine Liste anderer Elemente (content particles), als Auswahl (choice) oder als Reihenfolge (sequence) | <!ELEMENT Kapitel (KapTitel, (Para | Zwischentit)+) > |
| mixed content: | #PCDATA = Parsed character data = zulõssige Zeichen + XML-Tags, eventuell zusammen mit einer Liste anderer Elemente | <!ELEMENT Zwischentit (#PCDATA)> <!ELEMENT Para (#PCDATA | Unterpara | Abb)> |
| EMPTY | leeres Element: darf keinen Inhalt enthalten, kann aber Attribute haben (z.B. <BR/> oder <BR></BR> = Zeilenumbruch ) | <!ELEMENT BR EMPTY> |
| ANY | jegliche #PCDATA bzw. jedes definierte Element ist in jeder Reihenfolge und Hõufigkeit zulõssig | <!ELEMENT Diss ANY> |
Neben Inhalt k÷nnen Elemente auch Attribute und Werte haben. Attribute sind Meta-data f³r Elemente. In der DTD werden die Attribute und ihre zulõssigen Werte in einer attribute list declaration definiert:
| Syntax der attribute list declaration | Beispiel |
|---|---|
| <!ATTLIST element_name attribute_definition attribute_definition ..... > |
<!ATTLIST Beispiel id ID #IMPLIED n CDATA #REQUIRED status (Entwurf | endg³ltig) "endg³ltig"> |
Erklõrung der attribute list declaration:
| Erklõrung: element_name | Beispiel |
|---|---|
| Name des Elements oder der Elemente, die mit dieser attribute list verkn³pft werden sollen | para |
Die attribute_definition hat folgende Syntax:
| Syntax der attribute_definition | Beispiel |
|---|---|
| attribute_name attribute_type default_value | <!ATTLIST para secrecy (topsec | public) "public"> |
Erklõrung der attribute definition:
| Erklõrung: attribute_name | Beispiel |
|---|---|
| Name f³r die Attribute, die mit dem Element verkn³pft werden | secrecy |
attribute_type:
| Arten von attribute_types | Unterarten | Beispiele |
|---|---|---|
| String Type | CDATA null oder mehr Zeichen, wobei auch die reservierten Zeichen (mit Ausnahme von <) als normale Zeichen gelten | <!ATTLIST Dissertation R³ckentitel CDATA #REQUIRED>
<Dissertation R³ckentitel = "Billy K. Koala"> ... </Dissertation> |
| Tokenized Types | ENTITY eine externe binõre entity, die in der DTD definiert ist | <!ENTITY Abbildung1 SYSTEM "tuepfli.gif"
NDATA gif> <!ELEMENT Abbildung EMPTY> <!ATTLIST Abbildung File ENTITY #REQUIRED> <Abbildung File = "Abbildung1"> </Abbildung> (ENTITY als Platzhalter f³r Abbildung) |
| ENTITIES dasselbe wie ENTITY, aber mehrere Werte, durch Spatien getrennt | ||
| ID ein einmaliger Identifikator f³r das Element, auf den mit IDREF verweiesenwerden kann (wird immer als ID angegeben) | <!ATTLIST Kapitel³berschrift ID ID #REQUIRED>
<Kapitel³berschrift ID = "Kap 3"> ... </Kapitel³berschrift> |
|
| IDREF Referenz zu einer ID, die wo anders im Dokument definiert ist | <!ATTLIST Verweisung Vw IDREF #REQUIRED>
<Verweisung Vw = "Kap. 3"> ... </Verweisung> |
|
| IDREFS Liste von IDREFs, getrennt durch Spatien | ||
| NMTOKEN eine Verbindung alphanumerischer Zeichen | <!ATTLIST Formular Druckformat NMTOKEN #IMPLIED>
<Formular Druckformat = "A4"> </Formular> |
|
| NMTOKENS Liste von NMTOKEN-Werten, getrennt durch Spatien | <!ATTLIST Abbildung Abbildungsrand NMTOKENS #IMPLIED>
<Abbildung Abbildungsrand = "5 12 35 55"></Abbildung> |
|
| Enumerated Types: der Nutzer der DTD muss oder kann aus einer Aufzõhlung von M÷glichkeiten wõhlen | Name token group | <!ATTLIST Norm status (Entwurf | zurKorrektur | endg³ltig) #REQUIRED> <Norm status = "Entwurf"> ... </Norm> |
| NOTATION attribute type | <!ATTLIST mathFormel format NOTATION (tex | troff) #REQUIRED> <mathFormel format = "tex"> ... </mathFormel> |
default_value:
| M÷gliche Werte des default_value eines Attribute | Erklõrung | Beispiel |
|---|---|---|
| literal value | eine konkrete Zeichenfolge | <!ATTLIST para secrecy (topsec | public) "public"> |
| #FIXED {fixedvalue} | das Attribut muss den Wert {fixedvalue} haben; wenn das Attribut nicht angegeben wird, wird trotzdem der Wert {fixedvalue} angenommen; der Anwender kann den Wert nicht õndern | <!ATTLIST para secrecy (topsec | public) #FIXED "public"> |
| #REQUIRED: | Es gibt keinen default value: f³r jedes Element, das dieses Attribut enthõlt, muss der Nutzer einen Wert spezifizieren.; sonst gibt es eine Error-Meldung | <!ATTLIST Norm status (Entwurf | zurKorrektur | endg³ltig) #REQUIRED> |
| #IMPLIED: | das Attribut ist optional, wenn kein Wert angegeben ist, ³bergeht es die Software oder f³gt einen softwarespezifischen default value ein. Ist in den meisten DTDs der hõufigste default value | <!ATTLIST Paragraph Schrifttype CDATA #IMPLIED> |
Entities k÷nnen sein:
| Syntax der general_ENTITY |
|---|
|
<!ENTITY EntityName EntityDefinition> |
Entities in der DTD k÷nnen sein:
| Entity | Erklõrung | Beispiel einer Entity declaration |
|---|---|---|
| parsed = text entities: | enthalten Text, der dort, wo die Entity im Dokument steht, ins Dokument eingef³gt wird | <!ENTITY T³ "T³bingen, Univ., Diss.,"> |
| unparsed = binary entities | Hinweis auf ein externes binõres File (d.h. Teile, die nicht als XML behandelt werden) | <!ENTITY Abbildung1 SYSTEM "tuepfli.gif"
NDATA gif>
(NDATA = es handelt sich um Daten, die nur innerhalb der betreffenden Anwendung interpretiert werden k÷nnen) |
Parsed (text) entities werden im Dokument so gekennzeichnet:
| Syntax | Beispiel |
|---|---|
| &{EntityName}; | &T³; |
Wirkung bei parsed (text) entities: der Parser ersetzt immer, wenn er auf &entity_name; st÷▀t, dies durch das, was zwischen in der EntityDefinition steht.
| Text mit Markup | Aufgel÷st |
|---|---|
| &T³; 1999 | T³bingen, Univ., Diss., 1999 |
Parsed_Entity declarations k÷nnen sein:
| Erklõrung | Beispiel | |
|---|---|---|
| internal_ENTITY declarations | die EntityDefinition enthõlt den ganzen Text der ENTITY | <!ENTITY T³ "T³bingen, Univ., Diss.,"> |
| external_ENTITY declarations | die EntityDefinition verweist auf einen Ort, an dem sich der Inhalt der ENTITY befindet | <!ENTITY Kapitel1 SYSTEM "C:/payerde/cmc/cmcs01.xml"> (Damit kann man z.B. die einzelnen Kapitel eines Buches zusamenf³hren) |
(Diese beiden Formen sind auch bei parameter_ENTITIES m÷glich).
Eine Entity kann folgende Funktionen haben:
Entities erm÷glichen globales Ersetzen und Updating. Entities unterst³tzen auch Standardisierung, da eine Entity nur an einer Stelle, der entity declaration, definiert und formuliert wird.
| Syntax der parameter_ENTITY | Beispiel |
|---|---|
| <!ENTITY % entity_name "replacement_entity_text"> | <!ENTITY % Lebensdaten "(#PCDATA)"> <!ENTITY % Lebensdaten "EMPTY"> |
Bei Parameter Entities besteht der replacement_entity_text aus associated parameters.
Parameter Entities werden in den Bestandteilen der DTD durch %entity_name; gekennzeichnet
Parameter entities erm÷glichen es, sehr einfach durchgehende ─nderungen in der DTD durchzuf³hren.
Beispiel:
<!ENTITY % Lebensdaten "(#PCDATA)">
<!ELEMENT Lebensdaten %Lebensdaten;>
<!ELEMENT Alter %Lebensdaten;>
...
Ersetzt man nun
<!ENTITY % Lebensdaten "EMPTY">
dann werden in allen Elementen der DTD, die Lebensdaten enthalten, die Lebensdaten weggelassen.
Notations werden ben÷tigt, wenn bei der Verarbeitung von XML-Dokumenten einzelne Daten eine spezielle Behandlung erfordern. Typische Beispiele: mathematische Formeln, Graphiken, Sound, Video, SourceCode. Der Parser ³berweist dann die entsprechenden Teile an entsprechende Software
| Syntax der NOTATION_declaration | Beispiel |
|---|---|
| <!NOTATION notation_name SYSTEM "external_identifier">
(wenn sich die betreffende Software auf dem System des Anwenders befindet) |
<!NOTATION MathText SYSTEM "/usr/bin/tex" > ( = mathematischer Text ist zu bearbeiten mit einem Sub-Programm, das als usr/bin/tex gespeichert ist) <!NOTATION Gleichung SYSTEM "/usr/bin/eqn"> ( = mathematische Formeln sind zu bearbeiten mit einem Sub-Programm. das als /usr/bin/eqn gespeichert ist] |
| <!NOTATION notation_name PUBLIC "external_identifier">
(wenn sich die betreffende Software ÷ffentlich zugõnglich ist) |
<!NOTATION TeX PUBLIC "+//ISBN 0-201-13448-9::Knuth// NOTATION The TeXbook//EN"> |
XLink ist noch im Entwurfsstadium, deshalb k÷nnen hier nur die Grundz³ge wiedergegeben werden.
Der neuste Entwurf: http://www.w3.org/TR/WD-xlink. -- Zugriff am 21.6.1999
Zum Verstõndnis des Folgenden sind folgende Unterscheidungen und Definitionen n³tzlich:
Unterscheide:
XLink (XLL) ist eine XML-konforme Unter-Sprache, mit der man Verkn³pfungen (Links) in XML definieren kann. Im Unterschied zu den Links in HTML erlaubt XML zweierlei Links:
Simple Links: haben die in folgender ATTLIST angegebenen M÷glichkeiten:
| DTD | Erklõrung |
|---|---|
| <!ELEMENT
SimpleLink ANY>
<!ATTLIST SimpleLink
> |
XML:LINK: kann Wert simple f³r simple link
oder extended f³r extended link haben
HREF: resource locator von einer ganzen Ressource (mit der URL oder URN) oder einem Teil der Ressource (mit URL#Xpointer). XML erlaubt es, wenn man auf einen Teil einer Ressource zuzugreifen und nur diesen Teil zu ³bertragen) INLINE: ROLE: man kann der Anwendungssoftware mitteilen, was der Link bedeuted (z.B. Glossar, Hintergrund Information, Zitat ...), sodass die Anwendungs-Software die entsprechende Information direkt vom Link holt und entsprechend in die Darstellung einbaut (z.B. das in einer Fu▀note Zitierte wird im Volltext in die Fu▀note eingebaut) TITLE: gibt dem Nutzer Informationen ³ber den Link SHOW: kann folgende Werte haben
ACTUATE: kann folgende Werte haben:
BEHAVIOR: gibt an, wie der Link selber sich verõndern soll: z.B. ─nderung der Farbe vor und nach dem Ausf³hren des Links; auch andere M÷glichkeiten sind implementierbar CONTENT-ROLE: õhnlich wie ROLE (s.oben), aber f³r lokale Ressourcen CONTENT-TITLE: õhnlich wie TITLE (s. oben), aber f³r lokale Ressourcen |
Ein simple link schaut dann im Markup z.B. so aus:
<SimpleLink XML:LINK="simple" HREF="http.//www.payer.de">T³pflis Global Village Library</SimpleLink>
Extended Links:
Extended Links sollen erlauben:
Links zu einer ganzen Gruppe von m÷glichen Ressourcen (z.B. Nachrichten)
Filterung relevanter Links
Extended Links k÷nnen sein:
Inline Extended Links: der Link-Text ist Bestandteil des Links, d.h. die lokale Resource ist Teil des Links
Out-of-line Extended Links: Links zwischen Resources, wobei der Linkende Text au▀erhalb der gelinkten Resource liegt (Beispiel: ich rede ³ber Luther und Buddha, verkn³pfe also beide, ohne selbst Luther oder Buddha zu sein)
Inline Extended Link:
| DTD | Erklõrung |
|---|---|
| <!ELEMENT
ExtendedLink ANY>
<!ATTLIST ExtendedLink
>
|
Die ATTLIST f³r diesen INLINE extended link ist wie
die f³r den simple link (s.oben) mit zwei Unterschieden:
Bei Extended Links m³ssen nõmlich die sogenannten locators als eigene ELEMENTs definiert werden. Dies erlaubt, f³r ein linking element viele locators zu spezifizieren. |
| <!ELEMENT ExtendedLocator ANY>
<!ATTLIST ExtendedLocator
> |
Obige DTD kann im Markup z.B. so verwendet werden:
<ExtendedLink XML:LINK="extended">
CMC-Skript
</ExtendedLink> |
Dieser Link besagt nicht, was die Anwendungssoftware damit tun soll, sondern gibt der Anwendungssoftware alle Information, die sie f³r Linking braucht. Es ist z.B. denkbar, dass die Anwendungssoftware in diesem Fall alle Kapitel zu einem Buch zusammenf³gt, oder dass sie in einem Pop-Up-Fenster die Kapitel zu Wahl stellt.
Out-of-Line Extended Link:
Das eben genannte Markup-Beispiel w³rde mit einem Out-of-Line Extended Link so ausschauen:
<ExtendedLink XML:LINK="extended" INLINE="false">
</ExtendedLink> |
Ein solcher Link ist nicht an eine bestimmte Stelle des Dokuments gebunden (Inline). So k÷nnte z.B. die Software die Links checken bevor sie sie ³berhaupt anzeigt u.õ.
Weiterf³hrende Ressourcen zu XLL:
Die obige Darstellung folgt weitgehend:
Pardi, William J.: XML in action. -- Redmont, WA : Microsoft Press, ®1999. --- 329 S. : Ill. + 1 CD-ROM. -- ISBN 0735605629. -- S. 143 - 157. -- {Wenn Sie HIER klicken, k÷nnen Sie dieses Buch bei amazon.de bestellen}
XPointer ist noch im Entwurfsstadium, deshalb k÷nnen hier nur die Grundz³ge wiedergegeben werden.
Der neuste Entwurf: http://www.w3.org/TR/WD-xptr. -- Zugriff am 21.6.1999
XPointer dient der Verkn³pfung zur inneren Struktur eines XML-Dokuments. Es soll z.B. erm÷glicht werden, nur einzelne Teile eines Dokuments zu linken und zu ³bertragen.
XSL ist noch im Entwurfsstadium, deshalb k÷nnen hier nur die Grundz³ge wiedergegeben werden.
Der neuste Entwurf: http://www.w3.org/TR/WD-xsl/. -- Zugriff am 21.6.1999
XSL nutzt templates, die patterns enthalten. Einzelheiten mit einem durchgef³hrten Beispiel sind gut erklõrt in:
Pardi, William J.: XML in action. -- Redmont, WA : Microsoft Press, ®1999. --- 329 S. : Ill. + 1 CD-ROM. -- ISBN 0735605629. -- S. 162 - 192. -- {Wenn Sie HIER klicken, k÷nnen Sie dieses Buch bei amazon.de bestellen}
Interessierten ist die Darstellung dort sehr empfohlen.
Um XML in ein Einzelexemplar voll oder zumindest teilweise umzusetzen, bedarf es entsprechender Browser. Man kann mittels Scripting-Languages (z.B: JScript) selbst solche Umsetzungen programmieren. F³r Nõheres dazu wird auf die weiterf³hrenden Ressourcen verwiesen.
Als Beispiel eines XML-fõhigen Browsers sei Amaya (f³r MathML) genannt. Siehe unten 12.7.5.
| HTML -- HyperText Markup Language | f³r WWW; enthõlt sowohl Elemente der Ausformung als auch Elemente der Manifestation (Layout-Tags, Style sheets) s. Kapitel 13,2,2 |
|---|---|
| ISO 12083 | international standardisiert f³r Verlagswesen (entwickelt von Association of American Publishers): Autoren verwenden diese DTD, die Verlage wandeln sie dann in den verlagsspezifischen Stil um |
| DocBook | Industriestandard f³r technische Dokumentationen |
| TEI DTD -- Text Encoding Initiative DTD | Vor allem f³r sprach- und literaturwissenschaftliches elektronisches Publizieren |
| MIL-STD-38784 | US-Militõr-DTD f³r technische Handb³cher (innerhalb des CALS Project |
| DSSSL | international standardisierter Document Type f³r Dokumente, die Styles
oder andere Spezifikationen f³r Dokumente definieren (SGML Quelldokumente)
Yahoo Category:
|
Hintergrund und Geschichte:
Urspr³nglich von der Association of American Publishers (AAP) entwickelt wurde der Vorlõufer dieser DTD 1988 zum ANSI-Standard. Mit einigen ─nderungen wurde sie 1993 zum internationalen ISO-Standard. Im Auftrag der ISO [ http://www.iso.ch/. -- Zugriff am 19.6.1999] ist EPSIG (Electronic Publishing Special Interest Group) [http://www.oasis-open.org/cover/epsig.html. -- Zugriff am 21.6.1999] f³r den Unterhalt der Norm verantwortlich. Als ISO-Standard darf die Norm (mit Ausnahme von Fehlerkorrekturen) fr³hestens alle f³nf Jahre geõndert werden. Dies gibt der Norm eine gute Stabilitõt, macht sie aber auch etwas unbeweglich.
Zweck:
Statement of scope 1998: "This International Standard presents a reference document type definition which facilitates the authoring, interchange and archiving of a variety of publications. This document type definition is deliberately general. It is a reference document type definition which provides a set of building blocks for the structuring of books, articles, serials, and similar publications in print and electronic form. This International Standard is intended to provide a document architecture to facilitate the creation of various application-specific document type definitions." [URL: http://www.xmlxperts.com/scope.htm. -- Zugriff am 19.6.1999]
Besteht aus:
Anwendung Doctype declaration B³cher <!DOCTYPE book PUBLIC "ISO 12083:1994//DTD Book//EN"> Fortlaufende Sammelwerke <!DOCTYPE serial PUBLIC "ISO 12083:1994//DTD Serial//EN"> Unselbstõndige Werke (Artikel) <!DOCTYPE article PUBLIC "ISO 12083:1994//DTD Article//EN"> Mathematisches in obigen DOCTYPEs enthalten
Unterhalten von:
ISO. -- URL: http://www.iso.ch/. -- Zugriff am 19.6.1999
Erhõltlich:
Geb³hrenfrei: ISO 12083 Information / Dianne Kennedy. -- URL: http://www.xmlxperts.com/12083.htm. -- Zugriff am 18.6.1999. -- [Stellt alle ISO 12083 DTDs zur Verf³gung]
Beispiele aus der DTD f³r Book:
| Markup | Beispiele f³r ELEMENTs (in SGML) |
|---|---|
<book>
</book> |
<!ELEMENT (%doctype;) - - (front, body, appmat?, back?) +(%i.float;) > |
<front>
</front> |
<!ELEMENT front O O (titlegrp, authgrp, date?, pubfront?, (%fmsec.d;)*, toc?) > |
<titlegrp> [= Angabe von Sachtiteln]
</titlegrp> |
<!ELEMENT titlegrp O O (msn?, sertitle?, no?, title, subtitle?) > |
<authgrp> [= Verfasserangabe]
</authgrp> |
<!ELEMENT authgrp O O (author|corpauth|aff)* > |
<confgrp> [= Kongressangabe]
</confgrp> |
<!ELEMENT confgrp - - (no?, confname, date?, location?,
sponsor?) > <!ELEMENT confname - O (#PCDATA) > |
Weiterf³hrende Ressourcen zu ISO 12083:
Hintergrund und Geschichte:
DocBook wurde von HaL Computer Systems und dem Verlag O'Reilly & Associates 1991 entwickelt (DocBook Version 1.1). Darauf wurde DocBook vor allem von der Davenport Group diskutiert, einem Forum f³r Produzenten von Computer-Dokumentationen. Version 1.2 war stark von Novell und DEC beeinflu▀t.
1994 bekam die Davenport Group offiziell die Verantwortung f³r Pflege und Weiterentwicklung von DocBook. Version V1.2.2 erscheint. Unter der Obhut der Davenport Group wurde die Zielsetzung von DocBook sehr ausgeweitet. Novell und Sun, die gr÷▀ten Nutzer von DocBook, versuchten gr÷▀eren Einfluss zu bekommen.
1997 erschien DocBook Version 3.0. Viele der Teilnehmer der Davenport Group wechselten ihr Engagement von DokBook zu XML. Deswegen verlangsamte sich die Entwicklung von DocBook drastisch. Deswegen wurde die Verantwortung von DocBook an OASIS ³bertragen.
1998 wurde das OASIS DocBook Technical Committe gegr³ndet. Vorsitzender ist Eduardo Gutentag von Sun. Eine XML-konforme Version von DocBook wurde in Angriff genommen.
Zweck:
"DocBook is an SGML DTD maintained by the DocBook Technical Committee of OASIS. It is particularly well suited to books and papers about computer hardware and software (though it is by no means limited to these applications).
Because it is a large and robust DTD, and because its main structures correspond to the general notion of what constitutes a "book," DocBook has been adopted by a large and growing community of authors writing books of all kinds. DocBook is supported "out of the box" by a number of commercial tools, and there is rapidly expanding support for it in a number of free software environments. These features have combined to make DocBook a generally easy to understand, widely useful, and very popular DTD. Dozens of organizations are using DocBook for millions of pages of documentation, in various print and online formats, worldwide." [http://www.oasis-open.org/docbook/intro.html. -- Zugriff am 20.6.1999]
Besteht z.Zt. aus:
DOCTYPE declaration Doc Book 3.1. <!DOCTYPE Book PUBLIC "-//OASIS//DTD DocBook V3.1//EN"> Es gibt auch eine (noch nicht offizielle) XML-Version.
Unterhalten von:
DocBook Technical Committee (TC) von OASIS.
Erhõltlich:
Geb³hrenfrei: http://www.oasis-open.org/docbook/docbook/3.1/docbook.dtd. -- Zugriff am 20.6.1999
Struktur der DocBook DTD (vereinfacht!):
| Markup |
|---|
<Set> [= Sammlung im weiteren Sinn]
</Set> |
<Book>
</Book> |
| Beispiel einer einfachen BookInfo:
<BookInfo>
</BookInfo> |
Weiterf³hrende Ressourcen zu DocBook:
Organisationen:
Hintergrund und Geschichte:
1977 forderten Experten auf dem Gebiet elektronischer Texte ein einheitliches Kodierungsschema f³r elektronische Texte, da sonst ein Chaos unterschiedlichster L÷sungen entstehen w³rde
1987 versammelten sich in Poughkeepsie, New York Experten auf dem Gebiet elektronischer Texte. Sie stellten fest, dass das 1977 bef³rchtete Chaos eingetreten ist. Man einigte sich darauf, ein einheitliches Kodierungsschema f³r elektronische Texte zu entwickeln. Dazu beschloss man die Poughkeepsie Principles [URL: http://www-tei.uic.edu/orgs/tei/info/pcp1.html. -- Zugriff am 21.6.1999].
1990 wurde der erste ÷ffentliche Entwurf (TEI P1) ver÷ffentlicht. Es wurden 15 Arbeitsgruppen gegr³ndet, um die speziellen Bed³rfnisse von Spezialgebieten einzuarbeiten. Die einzelnen Kapitel wurden von 1992 bis 1993 ver÷ffentlicht (TEI P2).
1993 wurden alle bisher ver÷ffentlichten Teile nochmals revidert.
Im Mai 1994 erschien die erste nicht als Entwurf bezeichnete Fassung (TEI P3). Seither liegt der Schwerpunkt darauf, TEI verstõndlicher zu machen. Teile einer XML-Fassung (TEI-Lite) wurden bereits ver÷ffentlicht.
Zweck:
"The Text Encoding Initiative (TEI) is an international project to develop guidelines for the preparation and interchange of electronic texts for scholarly research, and to satisfy a broad range of uses by the language industries more generally." [http://www.uic.edu/orgs/tei/. -- Zugriff am 20.6.1999]
Sponsors:
"The TEI is sponsored by the Association for Computers and the Humanities (ACH), the Association for Computational Linguistics (ACL), and the Association for Literary and Linguistic Computing (ALLC). Major support for the project has come from the U.S. National Endowment for the Humanities (NEH), Directorate XIII of the Commission of the European Communities (CEC/DG-XIII), the Andrew W. Mellon Foundation, and the Social Science and Humanities Research Council of Canada." [http://www.uic.edu/orgs/tei/. -- Zugriff am 20.6.1999]
Besteht aus:
Unterhalten von:
TEI Consortium. -- URL: http://www.tei-c.org/. -- Zugriff am 18.6.1999
Erhõltlich:
Unentgeltlich; s. Weiterf³hrende Ressourcen
Markup-Beispiele zur TEI DTD:
<TEI.2>
</TEI.2> |
The University of Virginia Etext Center Header: TEMPLATE [http://etext.lib.virginia.edu/tei/uvatei4.html. -- Zugriff am 20.6.1999:
| <teiHeader type=aacr2>
<fileDesc> [= Beschreibung der elektronischen Ressource]
</fileDesc> <encodingDesc>
</encodingDesc> <profileDesc>
<revisionDesc>
</revisionDesc> </teiHeader> |
Weiterf³hrende Ressourcen zu TEI:
Organisationen:
Hintergrund und Geschichte:
Das US-Militõr und die R³stungsindustrie sind die gr÷▀ten Anwender von SGML. Deswegen sind die militõrischen SGML-Standards bei SGML-Entwicklern oft der praktische Hintergrund.
CALS (urspr³nglich = Computer-Aided Logistic Support; z.Zt. = Continuous Acquisition & Lifecycle Support) ist ein Projekt des U.S. Department of Defense und des U.S. Departement of Commerce zur elektronischen Erwerbung und Verwaltung von technischen Informationen, insbesondere zu Waffensystemen. Der SGML-Teil von Cals wurde seit 1987 entwickelt und wurde 1987 Militõr-Standard MIL-M-28001. ─hnliche militõrische SGML-Projekte laufen z.B. in Kanada, Schweden, Australien.
MIL-STD-38784 (Standard practice for manuals, technical: general style and format requirements) wird manchmal irrt³mlich CALS DTD genannt. Es gibt jedoch viele CALS DTDs, MIL-STD-38784 ist nur am bekanntesten wegen seines Tabellen-Modells, das zum de facto Standard f³r kommerzielle SGML Anwendungen geworden ist.
Zweck von MIL-STD-38784:
"This standard covers the general style and format requirements for the preparation of standard Technical Manuals (TM) .. and changes to standard TMs. This includes all technical documents which are assignet a TM identification number and are to be controlled by a TM management information system or are subject to requisition from an inventory control point. In addition to 'paper' delivery, this standard provides for electronic delivery of data through the use of the Document Type Definitions contained in Appendixes B trough E." [MIL-STD-38784 1.1]
Besteht aus:
MIL-Std-38784 (2 July 1995): Standard practice for manuals, technical: general style and format requirements / Department of Defense [US]
Erhõltlich:
Unentgeltlich: http://wpcdso1.wpafb.af.mil/. -- Zugriff am 20.6.1999
Markup-Beispiel zu MIL-STD-38784 (stark vereinfacht)
<doc>
</doc> |
Weiterf³hrende Ressourcen zu MIL-STD-38784 und CALS:
Organisationen:
The Air Force Product Data Systems Modernization (PDSM)
Program Office
Technical Manual Specifications & Standards (TMSS) Project. -- URL: http://wpcdso1.wpafb.af.mil/.
-- Zugriff am 20.6.1999. -- [Informationen zu MIL-STD-38784]
CONTINUOUS ACQUISITION & LIFE-CYCLE SUPPORT (CALS) / DEFENSE INFORMATION SYSTEMS AGENCY, Center for Standards, Information Processing Division, JIEO/CFS/JEBE. -- URL: http://www-cals.itsi.disa.mil/. -- Zugriff am 18.6.1999
Obwohl alle vier dargestellten DTDs im Wesentlichen dieselbe Zielsetzung haben, sind sie miteinander nicht kompatibel! Um das Problem der Kompatibilitõt in den Griff zu bekommen, ohne die Freiheit (und Weltanschauung) der Anwender zu tangieren, gibt es die M÷glichkeit Meta-DTDs zu entwerfen, sogenannte Architectural Forms. Architectural Forms werden in normalem XML/SGML definiert.
Zur Verarbeitung von Architectural Forms ben÷tigt man eine sogenannte Architectural Engine: Software (einen Parser), um Architectural Forms in einem XML/SGML Dokument zu verarbeiten.
Solche Architectural Engines sind James Clark's SP (http://www.jclark.com/sp/. -- Zugriff am 21.6.1999) bzw. JADE (http://www.jclark.com/jade/. -- Zugriff am 21.6.1999).
Der Standard f³r Architectural Forms ist:
ISO/IEC 10744:1997 [HyTime]: Architectural Form Definition Requirements. Frei erhõltlich: http://www.ornl.gov/sgml/wg8/docs/n1920/html/clause-A.3.html. -- Zugriff am 23.6.1999
Bei Architectural Forms muss man unterscheiden:
die abgeleitete konkrete DTD: client bzw. derived DTD
die meta-DTDs, die jeweils eine sogenannte base architecture definieren
Architectural DTDs k÷nnen bestimmen:
die Form von ELEMENTs
die Form von ATRRIBUTEs
die Form von NOTATIONs
Folgendes sehr vereinfachende Beispiel soll das Prinzip von Architectural Forms klar machen:
Entwurf einer Architectural Form f³r bibliographische Angaben nach der ISBD (International Standard Book Description) (sehr vereinfacht!):
| Markup | DTD |
|---|---|
<BibliogrBeschreibung>
</BibliogrBeschreibung> |
<!DOCTYPE ISBD PUBLIC "-//Payer/ISBD DTD//DE"
[ <!ELEMENT BibliogrBeschreibung (Titelangabe, Verfasserangabe, Ausgabebezeichnung?, Erscheinungsvermerk, Kollationsvermerk, Gesamttitel?, URN?)> .... ]> |
Diese Architectural Form kann man nun auf alle vier genannten DTDs anwenden, indem man durch sogenannte Processing instructions die analogen, aber nicht gleich benannten bibliographischen Bestandteile in die ISBD-Bezeichnung ³berf³hrt: die Processing Instruction besagt also, dass ein Programm, das aufgrund der Dokumente automatisch einheitliche bibliographische Beschreibungen erstellt, z.B. in Dokumenten nach ISO 12083 das ELEMENT titlegrp so behandeln soll, als ob dort die ELEMENT-Bezeichnung "Titelangabe" stehen w³rde.
| DTD | Entsprechungen | Instructions |
|---|---|---|
| alle DTD | Processing Instruction:
<?IS10744:arch name "ISBD"
|
|
| ISO 12083 | titlegrp -- Titelangabe authgrp -- Verfasserangabe .... |
<!ATTLIST titlegrp ISBD NMTOKEN #FIXED
"Titelangabe"> <!ATTLIST authgrp ISBD NMTOKEN #FIXED "Verfasserangabe"> .... D.h. ein Programm, das "ISBD" verarbeitet, liest die Notation |
| DocBook | BookBiblio --- Titelangabe authgrp -- Verfasserangabe ... |
<!ATTLIST BookBiblio NMTOKEN #FIXED "Titelangabe> <!ATTLIST authgrp NMTOKEN #FIXED "Verfasserangabe"> .... |
| TEI-Lite | title -- Titelangabe author -- Verfasserangabe publicationStm --- Erscheinungsvermerk ... |
<!ATTLIST title NMTOKEN #FIXED
"Titelangabe> <!ATTLIST author NMTOKEN #FIXED "Verfasserangabe"> <!ATTLIST publicationStm NMTOKEN #FIXED "Erscheinungsvermerk"> .... |
| MIL-STD-38784 | prtitle -- Titelangabe authnote -- Verfasserangabe ... |
<!ATTLIST prtitle NMTOKEN #FIXED "Titelangabe> <!ATTLIST authnote NMTOKEN #FIXED "Verfasserangabe"> ... |
Weiterf³hrende Ressourcen zu Architectural Forms:
Von 1983 bis 1987 entwickelt. SGML Anwendung zur Herstellung von B³chern, Zeitschriften und Zeitschriftenartikeln. Zweck ist u.a. die Erm÷glichung des Manuskriptaustauschs zwischen Autoren und Verlegern. Enthalten sind optionelle Element-Definitionen f³r komplexe Tabellen und wissenschaftliche Formeln.
An der Entwicklung beteiligt waren u.a.:
Diese Anwendung wurde besonders von den CD-ROM-Verlegern weitgehend angenommen. Als ANSI Z39.50 wurde sie amerikanischer Standard. Zu Z39.50 s. unten.
HyTime ist eine Anwendung von SGML f³r Hypermedia (Hypertext and Multimedia).
HyTime ist ISO-Standard 10744 (2. ed.: 1997). Die erste Version erschien 1992.
Wegen der rasanten Entwicklungen im Bereich der Hypermedia ist Hytime kein Standard, der alle Aspekte von Hypermedia umfasst. Hytime standardisiert z.B. nicht bestimmte Datenformate. Hytime standardisiert aber folgende Teilgebiete:
Hytime ist ein Standard f³r
links to anything, anywhere, at any time
HyTime ist gedacht f³r Integrated Open Hypermedia (IOH) Anwendungen:
IOH folgt dem bibliographischen Modell des Hyperlinking: m÷gliche "bibliographische" Verweisungen auf jeden Teil jedes Dokumentes durch eine standardisierte bibliographische Verweisung:
Weiterf³hrende Ressourcen zu HyTime:
Da XML kein Dokumenttyp ist, sondern eine Document definition language, besteht die M÷glichkeit, Document types zu definieren, die Metadaten in jedem Ausf³hrlichkeitsgrad enthalten. Damit k÷nnen u.a. auch Suchmaschinen gezielt z.B. nach Ver÷ffentlichungsgattungen, Autoren, Titeln usw. suchen. Als Beispiel diene ein stark vereinfachender Entwurf f³r eine XML-DTD f³r deutsche Dissertationen: Im Text der Dissertation werden sõmtliche Metadaten wie Titel, Autor, Erscheinungsjahr, Abstract usw. mit Markup markiert und sind so f³r eine maschinelle Titelaufnahme und Dokumentation bereitgestellt.
| Markup | Aus der DTD |
|---|---|
|
<Dissertation>
</Dissertation> |
<!DOCTYPE Dissertation PUBLIC ....
[ <!ELEMENT Dissertation (Titelblatt, Kapitel+, Zusammenfassung, Literaturverz, Lebenslauf) <!ELEMENT Titelblatt (Titel, Autor, Lebensdaten, WissInst, Jahr, ...)> <!ELEMENT (Titel | Autor | Lebensdaten | WissInst | Jahr | ...) (#PCDATA)> (PCDATA = keine Unterelemente,sondern nur zum Inhalt des Dokuments geh÷rige Zeichen) ... ]> |
Um einen Eindruck vom breiten Anwendungsspektrum von XML zu geben, werden im Folgenden in alphabetischer Reihenfolge der Akronyme einige XML-konforme Spezial-MLs genannt, die bisher entwickelt wurden bzw. an denen gearbeitet wird (ohne Anspruch, auch nur die wichtigsten genannt zu haben!):
Beispiel zu MathML: die Maxwell-Gleichung
| Darstellung im MathML-fõhigen Browser Amaya | Darstellung in "normalem" Browser |
|---|---|
| ▿
|
|
| Einzelne Bestandteile der Maxwell-Gleichung | Markup |
|
|
<mrow>
|
|
= |
<mo>=</mo> |
|
|
<mfrac>
</mfrac> |
|
|
<mrow>
|
|
= |
<mo>=</mo> |
|
|
<mrow>
|
Weitere Beispiele zu den Fõhigkeiten von MathML:
|
|
|
|
|
|
|
|
[Quelle der Screenshots von MathML-Darstellungen in Amaya: http://www.w3.org/Amaya/MathExamples.html. -- Zugriff am 21.6.1999]
Weiterf³hrende Ressourcen zu SGML/XML-Anwendungen:
Die unten genannte Ressource enthõlt sehr umfangreiche Kurzdarstellungen mit einer F³lle von Links zu Anwendungen und Projekten (unbedingt zu konsultieren!):
Yahoo Categories:
Organisationen:
Ressourcen in Printform:
Megginson, David: Structuring XML documents. -- Upper Saddle River, NJ : Prentice Hall, ®1998. -- 420 S. + 1 CD-ROM. -- ISBN 0136422993. -- [Von allen mir bekannten Darstellungen am besten f³r die Bed³rfnisse von Dokumentaren und Bibliothekaren geeignet. Empfehlenswert]. -- {Wenn Sie HIER klicken, k÷nnen Sie dieses Buch bei amazon.de bestellen}
Pardi, William J.: XML in action. -- Redmont, WA : Microsoft Press, ®1999. --- 329 S. : Ill. + 1 CD-ROM. -- ISBN 0735605629. -- {Wenn Sie HIER klicken, k÷nnen Sie dieses Buch bei amazon.de bestellen}
Zum nõchsten Kapitel:
Kapitel 13,1: OSI-Schicht 7: Application
Layer -- Anwendungsschicht, Teil 1