mailto: payer@hbi-stuttgart.de
Zitierweise / cite as:
Payer, Margarete <1942 - >: Computervermittelte Kommunikation. -- Kapitel 13, 2,2,1: OSI-7 -- Application Layer. -- Teil 2, 2: Die Anwendungsschicht im Internet: WWW -- World Wide Web. -- 1. HTTP und URI. -- Fassung vom 8. Juli 1999. -- URL: http://www.payer.de/cmc/cmcs13221.htm. -- [Stichwort].
Erstmals publiziert: 1995
▄berarbeitungen: 19. Juni 1997; 8. 7. 1999 [grundlegende ▄berarbeitung und Erweiterung]
Anlass: Lehrveranstaltungen an der HBI Stuttgart
®opyright: Dieser Text steht der Allgemeinheit zur Verf³gung. Eine Verwertung in Publikationen, die ³ber ³bliche Zitate hinausgeht, bedarf der ausdr³cklichen Genehmigung der Verfasserin.
Zur Inhalts³bersicht von Margarete Payer: Computervermittelte Kommunikation.
Das World Wide Web, das sich rapide durchgesetzt hat, basiert auf HyperText (besser Hypermedia). WWW verkn³pft Informationen aus der ganzen Welt miteinander: es verbindet die ▄bersichtlichkeit eines Menusystems mit den M÷glichkeiten der direkten Querverbindungen zu Texten, Bildern, Ton ³berall auf der Welt. WWW unterst³tzt alle oben genannten Zugõnge zum Internet.
WWW ist ein verteiltes System, d.h. viele WWW-Server sind beteiligt. Das System wurde von Tim Berners-Lee an CERN in der Schweiz entwickelt und 1991 freigegeben. Biographisches zu Tim Berners-Lee: http://ruku.com/timberners.html. -- Zugriff am 28.6.1999.
Der Client ben÷tigt dazu einen W3-Browser -- z.B. Netscape, MS Internet Explorer, Opera, Amaya -- mit dem man Hypermedia abrufen kann (z.B. Ton, sofern man eine Soundkarte hat, oder Video) -- oder den Browser Lynx, welcher nur Texte darstellt.
Die Hauptteile des Folgenden kann man sich leicht so einprõgen:
Weiterf³hrende Ressourcen zu WWW-Browsern:
Yahoo Categories:
Virtual Libraries:
Weiterf³hrende Ressourcen zum WWW allgemein:
Yahoo Categories:
Virtual Libraries:
Argus Clearinghouse Categories:
WWW:
Ressourcen in Printform:
Aus der Unmenge von Literatur sei nur genannt:
Powell, Thomas A.: HTML : the complete reference. -- 2. ed. -- Berkeley [u.a.] : McGraw-Hill, ®1999. -- 1130 S. : Ill. -- ISBN 0072119772. -- [Sehr gute Gesamtdarstellung]. -- {Wenn Sie HIER klicken, k÷nnen Sie dieses Buch bei amazon.de bestellen}
Wilde, Erik: Wilde's WWW : technical fundations of the World Wide Web. -- Berlin {u.a.] : Springer, ®1999. -- 594 S. : Ill. -- ISBN 3540642854. -- [Klar geschrieben, geht gut auf die neuesten Entwicklungen ein]. -- {Wenn Sie HIER klicken, k÷nnen Sie dieses Buch bei amazon.de bestellen}
HTTP ist ein relativ einfaches Anforderung-Antwort-Protokoll. HTTP stellt eine Verbindung nach TCP nur f³r die Dauer einer einzigen Dokumentanforderung her. F³r jede einzelne Dokumentanforderung wird eine neue Verbindung hergestellt. Au▀erdem erzeugt jede Inline Graphic in einem Dokument eine eigene, neue Verbindung zum Server, auf dem sich diese Graphik befindet. So kann die Anforderung eines einzigen HTML-Dokuments mehrfache TCP-Verbindungen zum selben oder verschiedenen Servern herstellen.
HTTP bestimmt zwei grundlegende Vorgõnge:
Request von Client an Server:
Beispiel ist die Anforderung der Ressource mit der URL: http://www.payer.de/cmc/cmcs01.htm
Syntax des HTTP-Head:
| [HTTP-Method] [Identifier] [HTTP-Version] [Zusõtzliche Request-Header (optional)] |
Beispiel:
GET /cmc/cmcs01.htm HTTP/1.0
If-Modified-Since: Tuesday, 29-Jun-99 00:00:00 GMT
Referrer: http://www.payer.de/cmclink.htm
Connection: Keep-Alive
User-Agent: Mozilla/3.0 (Windows 95; Internet Explorer)
Accept: image/gif, image/x-bitmap, image/jpeg, image/pjpeg, */*
Accept-Language: de, en
Accept-Charset: iso-8859-1,*,utf-8
Erklõrung:
HTTP-Method:
Folgende Request-Methods sind in HTTP 1.1 vorgesehen
| GET | fordert das durch den Identifier bezeichnete Objekt an |
| HEAD | fordert nur den HEAD des durch den Identifier bezeichneten Objekts an |
| OPTIONS | fordert Informationen ³ber den Server oder ³ber Methoden, die auf das bezeichnete Objekt angewandt werden k÷nnen, an |
| POST | Sendet Informationen an die Adresse, die durch den Identifier bezeichnet ist. Wird verwendet um auf Formularen (<FORM>) mit METHOD="POST" eingegebene Daten an ein CGI-Programm auf dem Server zu ³bergeben |
| PUT | Ladet File auf Server |
| DELETE | L÷scht (normalerweise ausgeschaltet) |
| TRACE | f³r diagnostische Zwecke |
Als optionale zusõtzliche Request-Header sind u.a. zulõssig:
| optionaler request-header | Beispiel |
|---|---|
| Accept: [MIME-type]/[MIME-subtype] | Accept: image/gif, image/x-bitmap, image/jpeg, image/pjpeg, */* |
| Accept-Charset: [Zeichensatz] | Accept-Charset: iso-8859-1,*,utf-8 |
| Accept-Encoding: [Kompressionstyp] | Accept-Encoding: x-compress |
| Accept-Language: [Sprache] | Accept-Language: de, en |
| Authorization: [Authorisations-Schema Authorisations-Daten] | Authorization: user joeblow:testpass |
| Content-length: [Bytes] (bei PUT und POST) | Content-length: 1805 |
| Date: [Datum und Zeit] | Date: Tuesday, 29-Jun-99 00:00:00 GMT |
| If-Modified-Since: [Datum und Zeit] | If-Modified-Since: Tuesday, 29-Jun-99 00:00:00 GMT |
| Proxy-Authorization: [Authorisations-Information] | Proxy-Authorization: joeblow: testpass; Realm: All |
| Referer: [URL] | Referer: http://www.payer.de/cmclink.htm |
| User-Agent: [Code des Browsertyps] | User-Agent: Mozilla/3.0 (Windows 95; Internet Explorer) |
| Cookie:[Cookie] | GET /index.html HTTP/1.0 Cookie: Kunde=Alois+Payer; Kundennummer:12345; (s.unten) |
Response of Server an Client:
Syntax des Response:
| [Status line] [Response Headers (meist optional)] |
Beispiel:
HTTP/1.0 200 OK
Content-length: 1500
Content-type: text/html
Date: Tuesday, 29-Jun-99 00:00:00 GMT
Server: Netscape-Commerce/1.12
Syntax der Status line:
| [HTTP-version] [Status-code] [Reason-String] |
Beispiel:
HTTP/1.0 200 OK [bei erfolgreichem Request]
HTTP/1.0 404 Not Found [wenn File nicht gefunden]
Wichtige Status-codes sind:
Einige wichtige Response Header:
| Syntax | Beispiele | Erklõrungen |
|---|---|---|
| Content-type: [>MIME-type]/[MIME-subtype] |
Content-type: text/html |
Aufgrund des Content-type-Header "wei▀" der Browser ob er Helper-Programme, Plugins oder dergleichen aufrufen mu▀. |
| Location: [URL] | HTTP/1.0 301 Redirect Location: http://www.payer.de/cmclink.htm |
Erm÷glicht bei Status code 301 (Moved permanently) bzw. 302 (Moved temporarily) Umleitung auf neuen Standort |
| Retry-After: [Sekunden bzw. Zeitpunkt] | Retry-After: 600 | Bei Status code 503 (Service unavailable): gibt an, wann Service voraussichtlich wieder zugõnglich ist |
| WWW-Authenticate: [Authentifizierungsschema] realm="[Bereich, f³r den Authentifizierung n÷tig ist]" | WWW-Authenticate: Basic realm="Nutzerdatenbank" | Bei Status code 401 (Unauthorized): fordert Authentifizierung an |
| Set-Cookie: [Angaben zu Cookie] | Set-Cookie: Kunde=Alois+Payer; path=/; domain=www.amazon.de expires=Fri 2-Jul-1999 00:00:00 GMT |
Setzt Cookie (s. unten) |
| Refresh: | in HTML-HEAD:
<META HTTP-EQUIV="Refresh" CONTENT="300"> |
F³r Nachladen bzw. Umleiten von Seiten |
Weiterf³hrende Ressourcen zu HTTP:
Yahoo Categories:
Virtual Libraries:
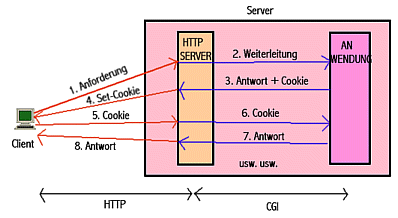
HTTP ist ein stateless (statusloses) Protokoll, d.h. es wird keine die einzelne ▄bertragung von Ressourcen und Objekten ³bergreifende Verbindung (wie z.B. eine Session) zwischen Client und Server hergestellt: jeder Request-Response-Austausch zwischen Client und Server ist unabhõngig von vorangehendem Request-Response-Austausch und ohne Einfluss auf darauffolgenden Request-Response-Austausch. Dies ist ein gro▀er Nachteil f³r zusammengeh÷rige Vorgõnge wie z.B. Einkauf in einen virtuellen "Einkaufswagen", den man erst am Schluss einer Sitzung abrechnet u.õ.
Zur L÷sung dieses Problems entwickelte Netscape sogenannte Cookies. RFC 2109 ³bernimmt im Wesentlichen diese L÷sung und ist mit den Netscape-Cookies kompatibel.
Der Grundgedanke von Cookies ist es, dass zwischen Server und Client Informationen ausgetauscht werden, die eine logische Sitzung konstruieren und identifizieren. Solche Identifikation kann dann auch ³ber die einzelne Sitzung hinaus verwendet werden, um einen Client wiederzuerkennen.
Den Vorgang illustriert folgende Abbildung:
Abb.: Herstellung einer Logischen Sitzung durch Cookie |
Erklõrung:
|
Cookies, die auf den eigenen Computer gesetzt wurden, kann man unter Windows im Verzeichnis: /WINDOWS/Cookies/ finden.
Das folgende Cookie hat den Filenamen "margarete payer@www.cookiecentral[2]". Auf dieses Cookie kann von au▀en nur der genannte Server zugreifen:
| Cookie | Erklõrung |
|---|---|
| lastHereOn | indentity |
| 930829314790 | indentity |
| www.cookiecentral.com/ | Domain name |
| 0 | |
| 215222400 | values, variables |
| 29291225 | values, variables |
| 473985120 | values, variables |
| 29279155 | values, variables |
| * | End Of cookie |
Was die Angaben zu values, variables bedeuten, kann man nur wissen, wenn man das CGI-Skript kennt (das der Nutzer normalerweise nicht kennt!).
Cookies werden vor allem genutzt zu:
Weiterf³hrende Ressourcen:
Yahoo Categories:
WWW:
FAQ:
Um sichere ▄bertragung mittels HTTP zu erm÷glichen, hat Netscape HTTPS -- HTTP over Secure Socket Layer (SSL) entwickelt. 1998 wurde dem W3Consortium ein Entwurf f³r HTTP over TLS vorgelegt, der mit HTTPS kompatibel ist. Bei HTTPS wird zwischen die Anwendungsschicht und die Transportschicht des Internets SSL als Protokoll-Zwischenschicht eingef³gt:
| Anwendungsschicht | http | ftp | telnet | usw. |
|---|---|---|---|---|
| Transportschicht | Secure Socket Layer (SSL) | |||
| TCP/IP | ||||
SSL erm÷glicht drei Formen der Sicherheit:
S-HTTP -- Secure Hypertext Transfer Protocol ist eine Alternative zu HTTPS und soll ebenso wie dieses den Austausch von verschl³sselten Daten (z.B. Zahlungsanweisungen per Kreditkartenangaben) ³ber das WWW erm÷glichen. Im Unterschied zu HTTPS ist shttp ein eigenes http-Protokoll. Die Protokoll-Schichtstruktur ist also:
| Anwendungsschicht | s-http | http | ftp | telnet | usw. |
|---|---|---|---|---|---|
| Transportschicht | TCP/IP | ||||
Das Grundprinzip von S-HTTP ist es, http-Dokumente in einer sicheren Form einzukapseln. Die Einkapselung hõngt nicht von der exakten Syntax des eingekapselten HTTP ab, ist also unabhõngig von der HTTP-Version.
Weiterf³hrende Ressourcen:
Yahoo Categories:
HTTP-ng soll gegen³ber HTTP 1.1 wesentlich verschieden sein. Die Arbeiten sind aber noch in einem so fr³hen Stadium, dass Aussagen dar³ber, wie HTTP-ng aussehen wird, noch nicht m÷glich sind.
Weiterf³hrende Ressourcen:
Yahoo Categories:
Organisationen:
Weiterf³hrende Ressourcen zu URI, URN, URL, URC :
WWW:
Yahoo Categories:
Um gezielt auf Dienste und Ressourcen im Internet zugreifen zu k÷nnen, wird inzwischen als L÷sung das Benutzen eines Uniform Resource Identifiers vorgeschlagen. (So wie das Verwenden von ISBN's).
Ein solcher Uniform Resource Identifier (URI) besteht aus drei Angaben:
An diese Standards werden u.a. folgende Anforderungen gestellt:
Wõhrend sich die anderen Teile der URI noch im Entwurfsstadium befinden, ist die URL ein anerkannter Standard, der sich weltweit durchgesetzt hat. Es handelt sich um eine Art Signatur bzw. die Angabe des Standorts und die Zugangsm÷glichkeit zu einer Internetressource.
Struktur des URL -- Uniform Resource Locator:
Vereinfachte Syntax einer URL:
| Zugangsprotokoll://Hostadresse:Port/Pfad |
Struktur: gopher://Hostadresse/Gopher_type_codeSelector_string
Gopher Type code = Gopher Resource Identifier Code (obsolete)
Selector_string entspricht dem Pfad
Struktur: mailto:Mailadresse
Struktur: news:Name der USENET-Gruppe
Struktur: nntp://Serveradresse/Name der USENET-Gruppe
(Da News Server sehr oft eine Zugangslegitimation verlangen, sollte man, wenn immer m÷glich das Linking mit news: verwenden.)
Beispiel:
http://www.well.com/user/payer/
Erklõrung:
Folgende verbreitete Webserver Software greift, falls im Pfad kein File angegeben ist, automatisch auf Files mit den betreffenden Namen zu:
Webserver Standardfilenamen NCSA HTTPD index.html CERN HTTPD Welcome.html welcome.html index.html WinHTTP index.htm MacHTTP default.html
▄bergabe von Suchbegriffen durch die URL:
Suchbegriffe f³r Such-Server k÷nnen in der URL ³bergeben werden, indem man die Suchstrings, durch + verbunden mittels eines Fragezeichens an die eigentliche URL anhõngt:
URL?Suchbegriff+Suchbegriff+Suchbegriff...
Tilde (~) in URL-Pfaden:
Nutzer auf manchen UNIX-Servern k÷nnen allgemein zugõngliche HTML-Dokumente in ihren eigenen home directories unterhalten. Die Pfade zu solchen Dokumenten haben eine Tilde (~) vor dem ersten Pfadeintrag. z.B.:
Reservierte Zeichen in URL-Pfaden (Kodierung mit %):
In ULS sind nur US-ASCII-Zeichen zulõssig, die nicht f³r die Kodierung reserviert sind. Verwendet man in Pfadangaben und Filenamen andere Zeichen, m³ssen sie kodiert werden.
Die folgende Liste gibt die wichtigsten Kodierungen an:
| Spatium | %20 |
| / | %2F |
| @ | %40 |
| & | %26 |
| % | %25 |
| \ | %5C |
Ein Filename "Einnahmen 1998.doc" m³sste also kodiert werden als "Einnahmen%201998.doc".
Probleme der URL:
Zuk³nftige URLs:
Das Internet wird zunehmend auch f³r Anwendungen verwendet, f³r die es urspr³nglich nicht vorgesehen war, wie:
Daf³r sind die jetzigen URLs nicht besonders geeignet, deshalb wird es wohl demnõchst URLs folgender Arten geben:
Weiteres zu zuk³nftigen Entwicklungen der URLs s.: http://www.w3.org/Addressing/. -- Zugriff am 4.7.1999
Weiterf³hrende Resosurcen zu URL:
Yahoo Categories:
Virtual Libraries:
Um den Schwierigkeiten der sich õndernden URL┤s aus dem Weg zu gehen und bei mehreren URL┤s f³r ein Objekt das Objekt sicher identifizieren zu k÷nnen, entwickelt man zur Zeit im Auftrag der Internet Engineering Task Force (IETF) die URN┤s. Ein Uniform Resource Name ist fest mit einem einzigen Objekt verbunden -- unabhõngig davon, auf welchem Server das Objekt liegt. Eine URN dient nicht dazu, etwas ³ber den Inhalt auszusagen. Wie die fr³here Aufl÷sung der Abk³rzung URN als Uniform Resource Number schon andeutete, besteht die URN im wesentlichen aus Ziffern und entspricht etwa einer ISBN. Hat das Werk schon eine ISBN, wird diese innerhalb der URN angegeben.
RFC 1737 stellt folgende Anforderungen an ein URN-System:
Bei der Entwicklung der URN┤s versucht man Automatismen zu entwickeln, die aus einer URN zu den URL`s f³hren k÷nnen. Wie man aus einer ISBN den Verlag bzw. die verantwortliche K÷rperschaft ablesen kann, soll ein Programm entsprechende Hinweise aus der URN entnehmen.
Syntax der URN: eine URN besteht aus drei Teilen, die jeweils durch Doppelpunkt voneinander getrennt sind
|
urn:[Namespace Identifier -- NID]:[Namespace Specific String -- NSS] |
| urn:[Namespace Identifier -- NID]:[Naming Authority]:[Opaque String] |
Beispiele f³r URNs aus Testprojekten:
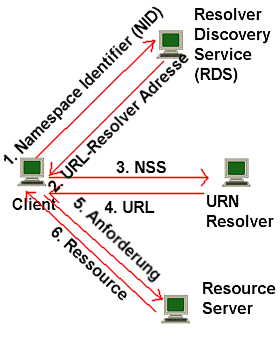
Die Vorgõnge bei der Aufl÷sung einer vollen URN zeigt folgendes Schaubild:
|
Abb.: Aufl÷sung einer URN |
Erklõrung:
Die Vorgõnge 1 und 2 k÷nnen auch entfallen, wenn der URN-Resolver bekannt ist (z.B. weil seine Adresse im Namespace Specific String genannt wird). |
Bevor die URN zum Standard erklõrt wird, muss u.a. noch geklõrt werden, was man als identischen Text ansieht: Soll einem ASCII-Text und einem Postskript-Text f³r ein identisches Werk eine oder zwei URN┤s zugeteilt werden? Wie weit gilt das auch f³r ▄bersetzungen? Die Tendenz scheint zur Zeit zu sein, dass man sich eher f³r nur eine URN entscheiden will, damit der Benutzer nicht viele URN┤s aufsuchen muss, nur um dann festzustellen, dass es sich um einen identischen Text handelt.
Weiterf³hrende Ressourcen zu URN:
Yahoo Categories:
Mailing-List:
Die PURL wurde von OCLC entwickelt, um aus dem Problem der sich õndernden URL┤s herauszukommen. Von der Funktion her ist die PURL eine URL, nur dass die PURL nicht direkt auf die Internetstelle verweist sondern auf einen dazwischengeschalteten Dienst. Dieser Dienst (zur Zeit auf einem Server bei OCLC) verbindet die PURL mit der jeweils aktuellen URL. Der Server sendet bei einer Anfrage mit der PURL dem Client die gerade aktuelle URL zur³ck, der Client benutzt dann die aktuelle URL. Ist die PURL bekannt -- d.h. wird sie in der Titelaufnahme angegeben -- , k÷nnen sich die URL┤s beliebig verõndern, und man findet den Text doch.
Syntax einer PURL:
|
http://[Resolver Adress]/[Name] |
| z.B.: |
Gebildet werden diese PURL┤s also in der ³blichen Weise mit dem verwaltenden Server als Hostadresse und dem entsprechenden Pfad: bei OCLC wird die Identifikationsnummer der dazugeh÷rigen Titelaufnahme genommen. Als Transportprotokoll wird grundsõtzlich http genommen. Da OCLC inzwischen die Software frei zur Verf³gung stellt, k÷nnten auch andere Institutionen z.B. Verbundzentralen einen solchen Weg gehen.
Beispiele von PURLs:
PURL kann man in sogenannten Service Requests verwendet werden. Die folgenden Beispiele machen die verschiedenen M÷glichkeiten des Zugriffs klar:oder ohne OCLC: http://purl.somewhere.edu/library/catalog
PURL Information Display Resolver Address: purl.oclc.org:80 (currently ignored) Local Name: /NET/INTERCAT PURL http://purl.oclc.org/NET/INTERCAT URL http://orc.rsch.oclc.org:6990 Maintainers EJUL Creation Date Fri Jan 5 14:45:30 1996 Last Modified Tue Feb 17 11:23:15 1998 Change Category User_Edited History Modified by EJUL Modified Tue Feb 17 11:21:58 1998 Change Category User_Edited URL http://www.oclc.org usw. usw. |
F³r jede Titelaufnahme wird eine PURL oder mehrere PURL┤s entsprechend der Anzahl der vorhandenen URL`s geschaffen und im MARC-Format in Kategorie 856 (subfield $u) abgelegt. Die eigentliche URL wird in 856 subfield $z (Public Note) erfasst, damit die darin enthaltene Information erhalten bleibt. Selbstverstõndlich muss gleichzeitig die URL in die OCLC-PURL-Resolver-Datenbank geschrieben werden.
Vorgõnge bei der Aufl÷sung einer PURL:
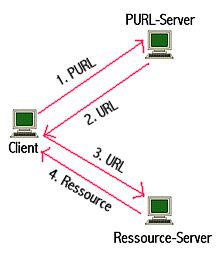
Abb.: Vorgõnge bei der Aufl÷sung einer PURL
Man stellt sich von OCLC aus vor, dass diese Datenbank weltweit genutzt wird. Um die Datenbank im Griff zu halten, d³rfen nur registrierte Nutzer PURL┤s erstellen und URL┤s zuordnen, bzw. Umleitungen durchf³hren. Der Berechtigte kann dies aber nur f³r die eigene Domain machen. Dass zwei identische PURL┤s entstehen, wird durch Programm verhindert. OCLC erwartet, dass ─nderungen in URL┤s von den Leuten, die URL┤s erstellen, an die Datenbank gemeldet werden. Und genau das ist die Schwachstelle des Vorschlags.
PURL┤s sollen im ³brigen nur f³r Texte vergeben werden, von denen man annnimmt, dass sie von bleibender Bedeutung sind, also z.B. f³r individuelle Artikel, aber nicht f³r einzelne Kapitel, Graphiken usw, Texte, die ohne Kontext unverstõndlich sind, vergõngliche Meldungen.
Die zuk³nftige Umwandlung von PURLs in URNs stellt man sich so vor:
| PURL | http:// | Resolver Adress | Name |
|---|---|---|---|
| http:// | purl.oclc.org | /keith/home | |
| URN | URN:/ | Naming Authority | Name |
| URN:/ | org/oclc/purl | /keith/home |
PURL Server k÷nnen auch Handles (s. unten) aufl÷sen. Beispiel:
http://purl.oclc.org/hdl/cnri-1/cnri_home l÷st die Handle cnri-1/cnri_home auf [Zugriff am 1.7.1999]
Was sind die Vorteile der PURL?
Weiterf³hrende Ressourcen zu PURL:
PURL Server:
Das Handle System« wurde vom CNRI (Corporation for National Research Inititiatives) entwickelt. Es ist ein System von bestõndigen Namen, die schnell in Adressen umgewandelt werden k÷nnen.
An Handle nehmen teil:
Ein Handle Resolver ist als Extension f³r den Netscape und MS Internet Browser frei erhõltlich: URL: http://www.handle.net/resolver/index.html. -- Zugriff am 1.7.1999.
Syntax einer handle:
|
[Naming Authority]/[Item ID] |
| z.B.:
10.1000/44 |
Die Naming Authority wird auch Prefix genannt, die Item ID Suffix.
Beispiele von Handles (k÷nnen ausprobiert werden, wenn Sie zuvor den Resolver auf Ihrem Computer installieren):
hdl:4263537/4006. -- Zugriff am 1.7.1999
hdl:10.1000/31. -- Zugriff am 1.7.1999
Funktionsweise eines Handle-systems:
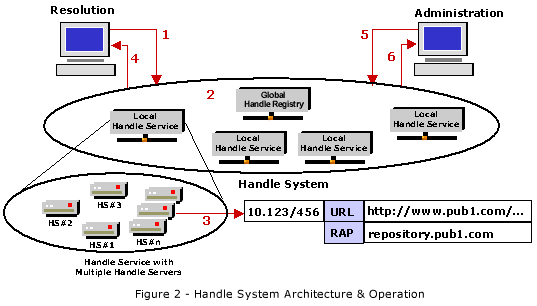
Abb.: Handle System Architecture & Operation
[Quelle und ® der Abbildung: http://www.handle.net/overviews/hs-version4.html. -- Zugriff am 1.7.1999]
Erklõrung:
Aufl÷sung der Handle
1. Ein Client sto▀t auf eine Handle (als Hyperlink), z.B. 10.123/456. Er sendet dies zu einem Handle System zur Aufl÷sung
2. Das Handle System besteht aus einer Anzahl von Handle Services. Jeder Service ist logisch und physisch auf eine Anzahl von Servern verteilt und kann gespiegelt werden. Eine einzige Global Handle Registry verwaltet die Adressen der f³r die einzelnen Naming Authorities zustõndigen Local Handle Services
3. & 4. Jede Handle ist im entsprechenden Handle Service mit (mindestens) einer Adresse (URL) und einem Protokoll Namens RAP verkn³pft. URL und RAP werden dem Client ³bermittelt, der damit auf die Ressource zugreifen kann
Verwaltung des Handle Systems:
5. Administrative Clients k÷nnen Handles und die Verkn³pfung mit URLs und RAP erzeugen
6. Das Handle System meldet dem Administrative Client, ob seine Hinzuf³gung einer Handle erfolgreich war oder nicht (weil z.B. fehlerhaft). Batch mode f³r Hinzuf³gungen und zum Editieren ist vorgesehen
Anwendungen von Handle:
Weiterf³hrende Ressourcen zum Handle System:
Bei der URC handelt es sich um eine Beschreibung einer Internet-Ressource, die beliebig tief gehen kann. Man stellt sich vor, dass man mit einer minimalen Beschreibung beginnt und jemand anderes, z.B. ein Katalogisierer, dann nach Bedarf noch weitere Elemente hinzuf³gt. Die URC kann sich zu einer sehr ausf³hrlichen Titelaufnahme entwickeln. Die Elemente der URC sollen so definiert werden, dass sie in unterschiedlichste Systeme ³bernommen werden k÷nnen.
Die URC muss mindestens die Angaben der URN und die URL (den physischen Standort) enthalten, oder nach neueren Vorschlõgen die URN und das Format (content type):
Beispiel f³r eine minimale URC:
<urc>
<urn>IANA:lanl.gov:LA-UR-94-00023
<location>http://www.acl.lanl.gov/...
Eine ausf³hrliche URC kann folgende zehn Elemente enthalten:
Jedes dieser Elemente kann verschiedene Ausf³hrlichkeitsgrade haben:
z.B. Element Verfasser:
Daniel, Ronald E. Jr
Daniel, Ronald E. Jr
Email: rdaniel@lanl.gov
Phone: 1 505 665 0139
Was verspricht man sich im wesentlichen von der URC?
Die Vorschlõge zur URC werden zur Zeit diskutiert, besonders:
Nachdem vom W3Consortium RDF -- Resource Description Framework [Siehe: http://www.w3.org/RDF/. -- Zugriff am 16.6.1999] entwickelt worden ist, ist mit einer erh÷hten Aufmerksamkeit f³r URC zu rechnen. Auch das Dublin Core (s. unten) soll RDF-konform gemacht werden.
S. auch unten zum META Tag in HTML.
Weiterf³hrende Ressourcen zu URC:
Yahoo Categories:
Mailing-List:
Wõhrend die URC urspr³nglich nur gedacht war, ³ber eine Besonderheit eines Textes zu informieren, und keineswegs eine Art Titelaufnahme darstellen sollte, wurde parallel ein Vorschlag (das Dublin Metadata Core Element Set) zur standardisierten Beschreibung von Daten in elektronischen Netzen entwickelt. Die Auswahl der Metadaten sollen zwischen den Angaben in den Suchmaschinen auf der einen Seite und den Angaben in vollem MARC-Format auf der anderen Seite liegen. Man wõhlte ausdr³cklich nicht ein verk³rztes MARC-Format, da man sich bewusst war, dass eine traditionelle Beschreibung auf viele Objekte im Netz nicht anwendbar ist. Au▀erdem will man erreichen, dass der jeweilige Verfasser selbst diese Daten in standardisierter Form seinen Texten beigibt, so dass man durch eine automatische Suche einen Katalog erstellen kann.
An der Entwicklung sind Organisationen wie OCLC, LoC, MARBI (das Gremium f³r MARC), SGML-Entwickler usw. beteiligt. Wesentliche Ergebnisse wurden auf einem ersten Workshop im Mõrz 95 beschlossen. Am Anfang der Entwicklung legte man wert darauf, dass der Standard sehr einfach ist, und dass es m÷glich sein sollte, mit Minimalangaben auszukommen, damit jeder Verfasser eine Beschreibung f³r seinen Text liefern kann. Die Elemente f³r die Minimalangaben wurden so ausgewõhlt, dass mit ihnen ein Wiederfinden der Quelle m÷glich ist. Au▀erdem grenzte man den Vorschlag auf dokumentenõhnliche Objekte (document-like objects) ein, wobei man bewusst keine genaue Definition gab: im weitesten Sinne handelt es sich um Text. Als Beispiele wurden genannt: elektronische Version eines Zeitschriftenartikels, ein W÷rterbuch, aber nicht eine elektronische Version einer Karte.
Offiziell gibt es seit 1996 15 Metadata-Elemente (urspr³nglich 13), die aber in den meisten laufenden Anwendungen keineswegs alle genommen werden:
Bei der Anwendung dieser Elemente ist allgemein folgendes zu beachten:
Da man inzwischen erkannt hat, dass man einen Gro▀teil der Elemente sinnvoll nur nutzen kann, wenn sie sich an ein normiertes Schema halten, - also z.B. bei Schlagworten einen verbindlichen Thesaurus, oder bei Namensansetzungen eine Normliste, wurden Dublin Core Qualifiers eingef³hrt. Au▀erdem muss man aus Gr³nden des Datentausches und des verlõsslichen Retrievals in weiteren Elementen zusõtzliche Angaben machen. Man unterscheidet bei den DC Qualifiers daher zwischen:
Wegen dieser Ausweitung der Regeln d³rfte es inzwischen f³r die meisten Verfasser von Internettexten nicht mehr m÷glich sein, die verlangten Angaben zu erbringen. Die Projekte, in denen DC eingesetzt werden, bieten daher den Verfassern Erfassungsformulare (sog. Templates) an, die dann von den entsprechenden Institutionen korrigiert werden (das geht bis zum sog. Hochkatalogisieren).
Beispiel des Templates des Bibliotheksservicezentrums Baden-W³rttemberg, Konstanz (gek³rzt):
Quelle: http://www.swbv.uni-konstanz.de/wwwroot/metadata/tp_dc00.html. -- Zugriff am 2.7.1999
|
Dublin Core Metadaten-Generator DC-Template
*** Entwicklungsversion ***
|
|
Thomas Dierig
--
E-Mail: thomas.dierig@bsz-bw.de
|
Um den Wildwuchs in den entstehenden Regeln und die Auseinandersetzungen zwischen Gruppen mit unterschiedlichen Einstellungen in den Griff zu bekommen, gibt es seit 1998 offizielle Gremien [siehe: http://purl.org/DC/about/index.htm. -- Zugriff am 2.7.1999]
Auch die Internet Engineering Task Force (IETF) setzt sich inzwischen f³r DC ein: RFC 2413 (Dublin Core Metadata for Resource Discovery) [URL: http://www.cis.ohio-state.edu/htbin/rfc/rfc2413.html. -- Zugriff am 2.7.1999] ist bekannt als DC 1.0. Diese RFC liegt zur Zeit der NISO (National Information Standards Organization) und der CEN (Center for European Normalization) vor. Bedingung f³r eine Anerkennung als offizielle Norm ist aber eine eindeutige Definition, die bei den Elementen von DC bisher nicht zu erkennen ist. So versucht man, die Bedeutung der Elemente mit der ISO-Norm 11179 (Specification and Standardization of Data Elements) in ▄bereinstimmung zu bringen.
Ein Beispiel aus dem SWB:
| Element | Markierung im HTML-HEAD |
|---|---|
| DC.DATE.CURRENT | <META NAME="DC.DATE.CURRENT" CONTENT="(SCHEME=ANSI.X3.30-1985) 19970715"> |
| DC.TITLE | <META NAME="DC.TITLE" CONTENT="Kreieren eines Dublin Core Metadaten-Eintrags"> |
| DC.CREATOR.NAME | <META NAME="DC.CREATOR.NAME" CONTENT="Dierig, Thomas"> |
| DC.SUBJECT | <META NAME="DC.SUBJECT" CONTENT="Dublin Core, Metadaten"> |
| DC.DESCRIPTION | <META NAME="DC.DESCRIPTION"
CONTENT="Konventionen zur Anwendung von Dublin Core Metadaten innerhalb Caroline. Innerhalb Caroline ist dies ein Teilbereich, in dem Werkzeuge zur Erfassung von Metadaten bereitgestellt werden."> |
| DC.PUBLISHER | <META NAME="DC.PUBLISHER" CONTENT="BSZ - Bibliotheksservice-Zentrum Baden-W³rttemberg"> |
| DC.CONTRIBUTORS.NAME | <META NAME="DC.CONTRIBUTORS.NAME" CONTENT="Wolf, Stephan"> |
| DC.TYPE | <META NAME="DC.TYPE" CONTENT="Service"> |
| DC.FORMAT | <META NAME="DC.FORMAT" CONTENT="(SCHEME=imt) text/html"> |
| DC.IDENTIFIER | <META NAME="DC.IDENTIFIER"
CONTENT="(SCHEME=URL) http://www.swbv.uni-konstanz.de/wwwroot/metadata/an_dc01.html"> |
| DC.SOURCE | <META NAME="DC.SOURCE" CONTENT="SWB-IDNR/00471187"> |
| DC.LANGUAGE | <META NAME="DC.LANGUAGE" CONTENT="(SCHEME=NISOZ39.53) GER"> |
| DC.COVERAGE | <META NAME="DC.COVERAGE" CONTENT="Germany"> |
| DC.RIGHTS | <META NAME="DC.RIGHTS" CONTENT="Public domain"> |
[Quelle: http://www.swbv.uni-konstanz.de/wwwroot/metadata/an_dc01.html -- Zugriff am 2.7.1999
Weiterf³hrende Ressourcen zu Dublin Metacore:
Organisationen:
Darstellung des Stands April 1999:
Zum nõchsten Kapitel: WWW2: HTML und CSSĀ (Computervermittelte Kommunikation)