mailto: payer@hbi-stuttgart.de
Zitierweise / cite as:
Payer, Margarete <1942 -- >: Computervermittelte Kommunikation. -- Kapitel 15: Datenbanken im Internet. -- Fassung vom 19. Juli 1999. -- URL: http://www.payer.de/cmc/cmcs15.htm. -- [Stichwort].
Erstmals publiziert: 19. Juli 1999
▄berarbeitungen:
Anlass: Lehrveranstaltung HBI Stuttgart, SS 1998
Unterrichtsmaterialien (gemõ▀ ¦ 46 (1) UrhG)
Copyright: Dieser Text steht der Allgemeinheit zur Verf³gung. Eine Verwertung in Publikationen, die ³ber ³bliche Zitate hinausgeht, bedarf der ausdr³cklichen Genehmigung der Verfasserin.
Zur Inhalts³bersicht von Margarete Payer: Computervermittelte Kommunikation.
Vorbemerkung: Dieses Kapitel setzt voraus:
Kapitel 13,2,2,3: Web-Programmierung und Suchmaschinen
In der Zeit vor dem WWW waren die 60er-Jahre die Zeit der Mainframe-Datenbanken. Das ANSI Committee on Data Systems Languages (CODASYL) entwickelte als Standard die Network Model Database. Als proprietõre L÷sung setzte IBM das hierarchische Datenbankmodell IMS (Information Management System) entgegen. CODASYL und IMS sind auch heute noch von gro▀er Bedeutung, da gro▀e Datenbestõnde sich auf solchen Systemen bilden und damit ein Erbe (legacy) oder auch eine Erblast darstellen.
Die Grundeinstellung in den ersten Jahrzehnten von Computerdatenbanken war zentralistisch: eine zentrale Datenverwaltung erm÷glicht bzw. erleichtert hohe Qualitõt im Unterhalt der Datenbank. Aus solchen Qualitõts³berlegungen heraus gibt es auch heute noch starke Bef³rworter zentraler L÷sungen.
Das urspr³ngliche Modell des WWW war statisch:
Nach diesem Modell erhielt jeder Nutzer dasselbe Dokument.
In einem zweiten Schritt kam CGI (Common Gateway Interface) hinzu. Es erlaubte Nutzern, dynamische Dokumente anzufordern, indem sie ein Formular ausf³llten mit ihrer spezifischen Anfrage. Diese Anfrage geht an den Daten-Server, der u.U. ³berlastet werden kann.
In einem dritten Schritt entwickelte man die Konzepte der dreistufigen WWW-Datenbank-Verbindung (Web database connectivity) und von webgest³tzter Middleware.
Das WWW-Datenbank-Verbindungs-Modell hat drei Schichten:
| Schicht | Technische Verwirklichung |
|---|---|
| Darstellungsschicht (Presentation tier) | Web Browser |
| Verarbeitungsschicht (Business logic tier) | Web Server Transaktions³berwacher Anwendungsserver |
| Datenschicht (Data tier) | Back-end Datenbanken und Mainframes |
In diesem Modell ist der Web-Browser der universale Client f³r Datenbankanwendungen: der Web-Browser ist die Benutzeroberflõche, die so bekannt ist, dass das Ideal "Datenbankzugang f³r jede Oma und jeden Opa" in Griffnõhe gekommen ist.
Die mittlere Schicht (Verarbeitungsschicht) erf³llt u.a. folgende Aufgaben:
Datenbankzugriff kann geschehen:
Man sagt, dass eine Anwendung Native Calls benutzt, wenn sie direkt die Libraries (unter Windows: DL -- Dynamik Linke Libraries) aufruft, mit denen der Datenbankserver Zugang zu den Daten schafft. Native Calls sind produktspezifisch und darum auf das bestimmte Produkt (z.B. Oracle, Informix, SQL Server) beschrõnkt.
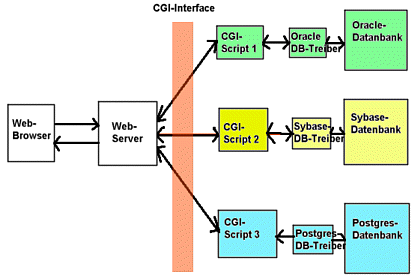
Abb.: Native Calls ³ber CGI-Scripts
Im in der Abbildung gegebenen Beispiel von drei ³ber einen Webserver mit dem WWW verbundenen Datenbanken muss der Programmierer f³r jedes Datenbankprodukt ein eigenes CGI-Script schreiben.
Im Unterschied zu Native Calls ist ein API (Application Programming Interface) eine (zumindest teilweise) produktunabhõngige Schnittstelle. Der Programmierer muss sich nicht um die spezifischen Eigenheiten der Anwendungen (Datenbanken) k³mmern, die dieses API unterst³tzen. Die Verbindung zwischen API und Anwendung (Datenbank) stellen produktspezifische Treiber her.
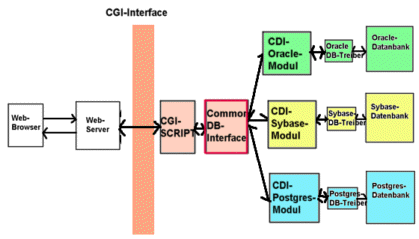
Abb.: Zugriff ³ber API bzw. standardisierte Schnittstelle (hier Common DB-Interface - CDI genannt)
Im in der Abbildung gegebenen Beispiel von drei ³ber einen Webserver mit dem WWW verbundenen Datenbanken muss der Programmierer im Unterschied zu Native Calls nur noch ein einziges CGI-Script schreiben, die anderen Module sind schon vorhanden
Es wurde eine Anzahl standardisierter Schnittstellen zum Zugriff auf heterogene Datenbanken entwickelt:
Die wichtigsten sind:
Standardschnittstellen erm÷glichen es dem Programmierer in der Theorie, die Datenbanksysteme als Black Boxes zu betrachten, d.h. sich nicht um ihre Innereien k³mmern zu m³ssen. Die Praxis sieht leider etwas anders aus:
"In a perfect world, the black box technique operates like an electrical outlet: You plug into a receptacle and your program works without requiring any additional intelligence. If you need solutions for writing interoperable SQL [Standard Query Language] programs, you will find that ODBC and JDBC are useful technologies. They do not deliver 100 percent of the promise of the black box and they don't produce a black box effect that is comparable to the Java APIs and the Java VM [Virtual Machine]. You will find however, that ODBC and JDBC include functions and methods, respectively, that are useful for writing portable database code."
[North, Ken: Database magic with Kan North. -- Upper Saddle River, NJ : Prentice Hall, ®1999. -- ISBN 0136471994. -- S. 328. -- {Wenn Sie HIER klicken, k÷nnen Sie dieses Buch bei amazon.de bestellen}.
ODBC wurde 1992 von Microsoft entwickelt. Es ist eine von Microsoft entwickelte Schnittstelle f³r heterogene Datenbanken, die SQL unterst³tzen. Es gibt aber auch ODBC-Treiber f³r Nicht-SQL-Datenbanken, f³r Spredsheet Programme, Lotus Notes usw.
ODBC ist sehr verbreitet, weswegen Grundkenntnisse von ODBC f³r jede mit Datenbankentwicklung Beschõftigte unerlõsslich sind.
Von ODBC existieren mehrere Versionen, was zu Problemen f³hren kann.
ODBC hat folgende Eigenschaften:
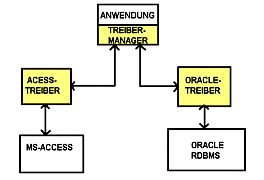
Abb.: Struktur von ODBC (Beispiel)
Weiterf³hrende Ressourcen zu ODBC:
Yahoo Categories:
http://dir.yahoo.com/Computers_and_Internet/Software/Databases/ODBC/. -- Zugriff am 19.7.1999
OLE DB ist eine von Microsoft entwickelte Schnittstelle (offener Standard) f³r verschiedene Datenbanken, auch solche, die SQL nicht unterst³tzen. OLE DB beruht auf Komponenten.
Active Server Pages (ASP) wurde von Microsoft f³r den Microsoft Information Server (IIS) 3.0 (Bestandteil von Windows NT 4.0) entwickelt, um die Schwierigkeiten f³r Programmierer mit ISAPI zu erleichtern, indem auf Seiten des Servers Scripts in VBScript erm÷glicht wurden (solche Files haben die Erweiterung .ASP statt .HTML). ASP enthõlt eine Datenquellenzugriffskomponente (Database Access Component). Diese verwendet f³r den Zugriff auf Datenquellen (Datenbanken, Tabellenkalkulationen, strukturierte Textdateien) ActiveX Data Objects (ADO). ADO arbeitet mit OLE DB, einer einheitlichen objektorientierten Schnittstelle f³r beliebige Datenquellen. Man kann bei Verwendung von OLE DB also die verwendete Datenbank austauschen, ohne den Programmcode in ASP modifizieren zu m³ssen. OLE DB hat auch eine Schnittstelle zu ODBC, so dass ³ber OLE DB auch alle Datenbanken zugõnglich sind, die ³ber ODBC zugõnglich sind.
Advanced Data Connector (ADC) ist ein Server- und Client-gest³tztes Werkzeug, das erlaubt, dass Daten aus einer Datenquelle in einer Ladung auf den Client ³bertragen und auf dem Client bearbeitet und verõndert (z.B. upgedated) werden und dann wieder in einer Ladung zur Datenquelle geschickt werden.
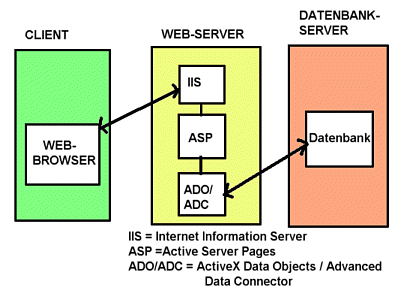
Abb.: Architektur einer Datenbankanbindung mit ASP/ADO/OLE DB
Weiterf³hrende Ressourcen zu OLE DB:
OLE DB resource center. -- http://www.oledb.com/. -- ["With an emphasis on member-generated content, oledb.com offers a variety of high-quality, published resources explaining OLE DB, Open Database Connectivity (ODBC), ActiveX Data Objects (ADO) and Universal Data Access."]. -- Zugriff am 16.7.1999
JDBC ist eine von JavaSoft (Tochterfirma von Sun) entwickelte Schnittstelle (API) f³r Java-Programme. JDBC erm÷glicht Java Programmen, ³ber SQL-Befehle auf Datenbanken zuzugreifen. Im Gegensatz zu ODBC ist JDBC auf eine einzige Programmiersprache beschrõnkt.
Weiterf³hrende Ressourcen zu JDBC:
Assfalg, Rolf ; Goebels, Udo ; Welter, Heinrich: Internet-Datenbanken. -- Bonn : Addison-Wesley-Longman, 1998. -- ISBN 3-8273-1230-2. -- S. 17 - 25 unterscheiden folgende Architekturen datenbankbasierter Internet-Anwendungen:
Man verwendet spezielle Reportgenerator-Schnittstellen f³r die Datenbank, die Ausgaben in HTML erzeugen. Diese Seiten kann dann jede Art von Webserver verwenden. Auf Seiten des Webservers sind dabei keinerlei speziellen Erweiterungen erforderlich. Diese L÷sung ist sinnvoll, um tabellarische Standardausgaben (z.B. B÷rsenkurse, Wettermeldungen, Abfahrtszeiten und Verspõtungen und dergleichen) zu erstellen. Der Benutzer hat keine M÷glichkeit, die erzeugten Dokumente zu beeinflussen.
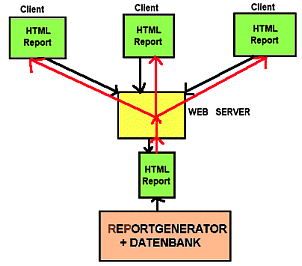
Abb.: Reportgenerator-Architektur
Der Webserver erhõlt mittels Native Calls, einer standardisierten Schnittstelle (ODBC, JDBC) oder einer proprietõren Datenbank-API Datenbankzugriffsfunktionen (diese werden mittels Skripts gesteuert):
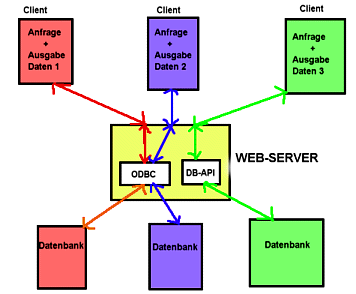
Abb.: Webserver mit Datenbankzugriff
Schema eines Datenbankzugriffs auf Web mittels CGI oder eines API (Application Programming Interface
Browser (Formular) --> HTTP --> Webserver --> CGI/FastCGI/ISAPI/NSAPI (usw.) --> Database Client (Web Service) --> Database Server --> Physikalisches Speichermedium der Datenbank -->retour
| CGI -- Common Gateway Interface | offener Standard (nicht von bestimmten Produkten oder Betriebssystemen abhõngig) |
|---|---|
| ISAPI -- Internet Server Application Programming Interface | Von Process Software und Microsoft als Alternative zu CGI f³r den Internet Information Server (IIS) entwickelt (auch von einigen Servern anderer Hersteller unterst³tzt) |
| NSAPI -- Netscape Server Application Programming Interface | Von Netscape Communications Corp, als Alternative zu CGI entwickelt. Lõuft nur auf Netscape Servern |
Das Datenbanksystem wird um die Funktion des Webservers erweitert. Bei diesem Ansatz sind Webserver und Datenbanksystem integriert, so dass man sich nicht um die Konfiguration von Schnittstellen und die Daten³bergabe usw. k³mmern muss.
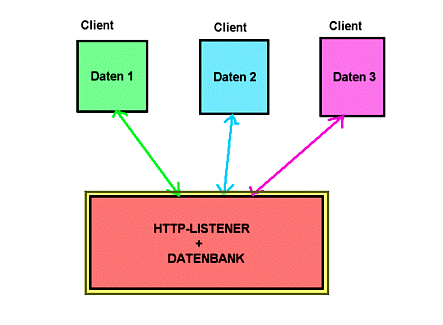
Abb.: Erweiterung eines vorhandenen Datenbanksystems als Webserver
Dies ist ein modularer Ansatz. Der Umgang mit Komponenten ist f³r Entwickler im Allgemeinen einfacher als durchgehende Programmierung.
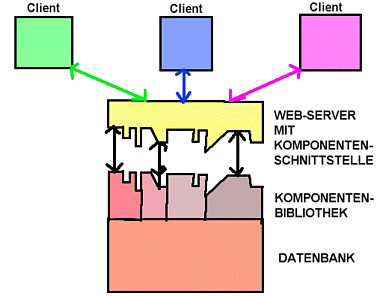
Abb.: Webserver mit Komponentenschnittstelle
Man verwendet Standard-Schnittstellen wie CGI (Common Gateway Interface).
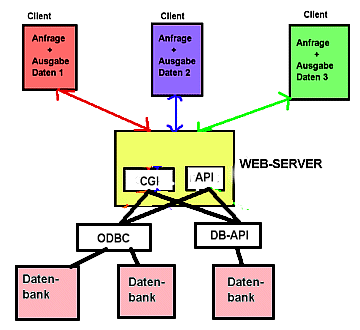
Abb.: Standardgateways
Problem:
Um diese Probleme zu l÷sen, bedarf es einer gemeinsamen, universellen Schnittstelle. Diese Schnittstelle bildet den Middleware Layer.
Der Middleware Layer muss eine Anzahl von Problemen l÷sen:
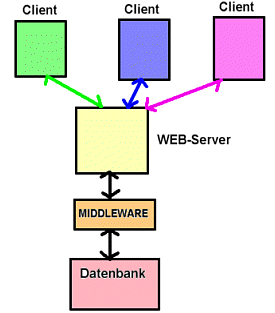
Abb.: Middleware
Bei einer einstufigen (Single-Tier) ODBC-Architektur ben÷tigt der Client datenbankspezifische Software (deshalb ist diese Architektur einstufig: der Client arbeitet in der datenbankspezifischen Stufe)
| SERVER A | CLIENT | SERVER B | |
|---|---|---|---|
DATENBANK System A |
Anwendung |
DATENBANK System B |
|
ODBC-Treiber-Manager |
|||
Spezifischer |
Spezifischer |
||
Kommunikations- |
Kommunikations- |
Kommunikations- |
Kommunikations- |
NETZWERK |
|||
Bei einer mehrstufigen (multi-tier) ODBC-Architektur liegt alle datenbankspezifische Software nur auf den Servern.
| SERVER A | CLIENT | SERVER B | ||
|---|---|---|---|---|
DATENBANK System A |
Anwendunng |
DATENBANK System B |
||
Datenbank A - Agent |
Request Broker |
Datenbank-unabhõngige ODBC Treiber- / Kommunikations-Schicht |
Request Broker |
Datenbank A - Agent |
NETZWERK |
||||
Beim Server gibt es einen Request Broker, der zustõndig ist f³r die Datenverbindung, Sicherheit und Berechtigungs³berpr³fung. Danach ³bergibt der Broker die Kommunikation an den Datenbank Agenten.
Eine zweistufige Architektur verlegt meist sehr viel in den Client. Das kann den Nachteil haben, dass jede ─nderung im Datenbanksystem zu einer ─nderung der Client-Software f³hrt mit allen Problemen der Verteilung dieser Software, der rechten Installation und Wartung.
Die hõufigste mehrstufige Architektur ist die dreistufige:
| Benutzerschnittstellenschicht (User Interface Layer) |
|---|
| Transaktionsschicht (Business Rules Layer) |
| Datenbankzugangsschicht (Database Access Layer) |
Eine solche Architektur hat den Vorteil, dass sie die Benutzerschnittstelle durch den Business Rules Layer von der eigentlichen Datenbank isoliert und so ─nderungen des Datenbanksystems erlaubt, ohne dass die Benutzerschnittstelle geõndert werden muss.
Verteilte Systeme sind eine ▄berwindung klassischer Client-Server-Systeme, insofern als jeder Teilnehmer am System anderen Teilnehmern Dienste anbieten kann. Die Dienste werden als Objekte (Komponenten) definiert. Schnittstellen zu den einzelnen Komponenten teilen anderen Komponenten mit, welche Dienste von dieser Komponente angeboten werden und wie diese Dienste genutzt werden k÷nnen. Solange die Schnittstelle nicht verõndert wird, kann die Implementierung der Komponente grundlegend verõndert werden (z.B. ─nderung des Datenbanksystems von relational zu objektorientiert), ohne dass dies andere Komponenten beeinflusst. Die Schnittstelle definiert das Protokoll des Verkehrs zwischen der Komponente und anderen Komponenten.
Das WWW ist eine Form eines verteilten Systems.
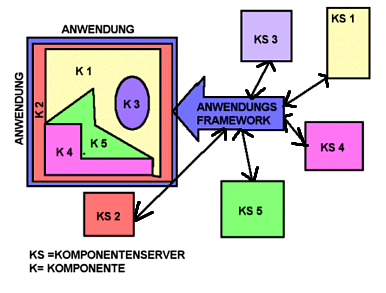
Abb.: Komponenten in einem verteilten System
Anforderungen an ein verteiltes Datnbanksystem sind:
Verteilte Systeme kann man als mehrstufige Client-Server-Systeme ansehen, die zusõtzlich noch ³ber Directory Services die Lokalisierung und Adressierung der Anbieter einzelner Dienste erm÷glichen.
Au▀erdem ist, um die Konsistenz des Systems zu erhalten ein Transaction Monitor n÷tig, d.h. ein Programm, das gewõhrleistet, dass Systeminhalte verõndernde Transaktionen an allen relevanten Stellen durchgef³hrt werden und dass sie nur durchgef³hrt werden, wenn an allen relevanten Stellen die Transaktion gelungen ist (Beispiel: eine bibliographische ─nderung wird entweder an allen lokalen Stellen durchgef³hrt oder gar nicht: wenn also die ─nderung an einer lokalen Stelle nicht gelingt, weil z.B. der Server down ist, dann wird die ─nderung nirgends durchgef³hrt, sondern die ─nderungstransaktion wird so lange versucht bis sie ³berall gelingt.)
Werkzeuge zur Entwicklung verteilter Systeme sind u.a. (alle komplexeren sind noch in der Entwicklung):
| Socket Pragramming ³ber Application Programming Interface (API) | f³r weniger komplexe Datentypen geeignet |
|---|---|
| Remote Procedure Call (RPC) | RFC 1831. -- URL: http://www.cis.ohio-state.edu/htbin/rfc/rfc1831.html.
-- Zugriff am 17.7.1999
RPC erm÷glicht den Aufruf von Programmen, Subprogrammen und Programmkomponenten auf einem anderen Computer |
| Open Group [fr³her: Open Software Foundation (OSF] Distributed Computing Environment (DCE) | OSF DCE ist ein herstellerneutraler Industriestandard f³r
verteilte Systeme mit den daf³r notwendigen Teilkomponenten.
Nõheres siehe: http://www.opengroup.org/dce/ -- Zugriff am 17.7.1999 |
| CORBA -- Common Object Request Broker Architecture | s. unten |
| Microsoft's Distributed interNet Application Architecture (DNA) mit DCOM | s. unten |
| JPE -- Java Platform for the Enterprise | s. unten |
Weiterf³hrende Ressourcen zu verteilten Systemen:
Ressourcen in Printform:
Weber, Michael: Verteilte Systeme: Heidelberg [u.a.] : Spektrum, ®1998. -- 376 S. : Ill. -- ISBN 3827402212. -- [Brauchbare ▄bersicht]. -- {Wenn Sie HIER klicken, k÷nnen Sie dieses Buch bei amazon.de bestellen}
Verteilte Systeme sind "Objekt-Orientiert". Der Begriff stammt aus der objekt-orientierten Softwareentwicklung (object-oriented programming, OOP). OOP beruht auf sieben Grundkonzepten:
Als (nicht ganz exakte) Analogie kann man verwenden:
Beispiel f³r Objekt, Attribute, Operationen (Methoden):
Obiges Auswahlkõstchen kann man als Objekt so darstellen:
| Objekt "Auswahlkõstchen" | |
|---|---|
| Attribute | Operationen (Methoden) |
| Gr÷▀e | Drop-Down-Men³ ÷ffnen |
| Auswahlmethode | eine Option auswõhlen |
| Liste der Optionen | Drop-Down-Men³ schlie▀en |
Am wichtigsten f³r den Benutzer ist Verkapselung (encapsulation): man stelle sich vor, dass man z.B. bei jedem Modell jedes Personenaufzugs jedes Herstellers zur Benutzung wissen m³sste, wie das System funktioniert. Statt dessen hat der Aufzug eine allgemeinverstõndliche ÷ffentliche Schnittstelle (public interface): die Kn÷pfe mit den Beschriftungen bzw. Symbolen f³r "Hinauf", "Hinunter", Stockwerksnummern, "T³r ÷ffnen" usw. So sind Nutzer einer Computerdienstleistung im Allgemeinen nur daran interessiert, welche Dienstleistungen angeboten werden und wie man diese Dienstleistungen in Anspruch nehmen kann.
Objekt-orientierte Softwareentwicklung strebte zunõchst die drei R's an:
Da sich die Erwartungen an Objekte nicht erf³llt haben, tritt allmõhlich an die Stelle der objektorientierten Softwareentwicklung (OOP) die Komponentenorientierte Softwareentwicklung (Component-Oriented Programming, COP). Eine Komponente ist in diesem Sinne eine Gruppe von Objekten, die hinter einer gemeinsamen Schnittstelle verborgen (Verkapselt) sind. Komponenten sind Einheiten f³r Wiederverwertung, Plug-in Software-Module. Komponenten sind nicht Objekte im strengen Sinn: es fehlt ihnen z.B. das Merkmal der Vererbung.
Weiterf³hrende Ressourcen zu Objektorientiertheit und Komponenten:
Yahoo Categories:
News:
Organisationen:
Virtual libraries:
| "Ich glaube, Corba selbst ist nicht so schwer, aber
verteilte Systeme zu entwickeln ist hart."
Richard Soley, Chief Engineering Officer der OMG. -- In: Computerwoche. -- 28/1999. -- S. 16. |
| CORBA ist eine Spezifikation, die die Definition der Schnittstellen in verteilten Systemen sowie die Kommunikation zwischen diesen Schnittstellen erm÷glicht. CORBA ist systemunabhõngig und auch nicht an eine bestimmte Programmiersprache gebunden. |
CORBA wurde 1991 von der OMG (Object Management Group) [URL: http://www.omg.org/. -- Zugriff am 13.7.1999] als Spezifikation ihrer Object Management Architecture (OMA) vorgestellt.
Die OMG wurde im April 1989 gegr³ndet, Gr³ndungsmitglieder waren u.a. 3Com Corporation, American Airlines, Canon, Inc., Data General, Hewlett-Packard, Philips Telecommunications N.V., Sun Microsystems,Unisys Corporation.
Jedes Mitglied der OMG kann Vorschlõge zur Erweiterung von CORBA einbringen: Spezifikationen, die nicht innerhalb eines Jahres implementiert sind, werden gestrichen. Normalerweise werden neue Spezifikationen gleichzeitig mit Implementierungen eingebracht.
Die von OMG entwickelte Object Management Architecture hat folgende Struktur:
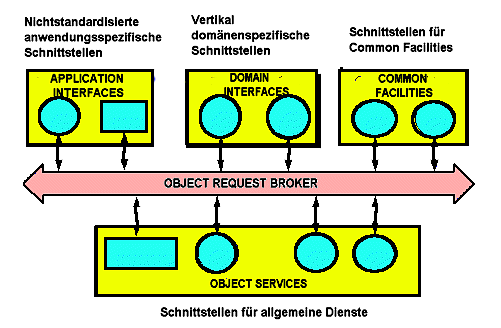
Abb.: Object Management Architecture (OMA)
[Vorlage der Abb.: http://www.omg.org/oma/. -- Zugriff am 13.7.1999]
Man kann diese Object Management Architektur auch als Schichtenmodell darstellen:
Application Layer -- Anwendungsschicht |
|
Common Facilities Layer (CORBAFacilities) Anwendungsschnittstelle f³r Anwendungen, die von mehreren anderen Anwendungen gemeinsam genutzt werden |
Vertical Frameworks Gemeinsame Ressourcen f³r spezielle Anwendungstypen und spezielle Anwendergruppen: z.B. Rechnungswesen, Graphik, Kraftstoffindustrie ... |
Horizontal Frameworks Gemeinsame Ressourcen, die nicht so grundlegend sind wie CORBA-Services, z.B. Benutzeroberflõche f³r zusammengesetzte Dokumente, Informationsverwaltung (Speicherung und Interaktion der Komponenten zusammengesetzter Dokumente), Task Management, Systemverwaltung (Einloggen, Sicherheit, Transaktionsmanagement), e-mail, , |
|
Object Services Layer (CORBAServices) Grundlegende Dienste f³r alle Objekte wie z.B. Adressierung, Lebenszyklus (Mitteilung an die von einer Anwendung genutzten Objekte, dass die aktuelle Nutzung beendet ist), Event Service (Erstellung eines Kommunikationskanals, durch den ein Objekt auf Vorgõnge wie z.B. Tastatureingabe, Mausklick wartet) |
|
Object Request Broker (ORB) Layer regelt die Kommunikation zwischen den Objekten. Erm÷glicht das Auffinden von Diensten. Bereitet das Zielobjekt vor, damit es Anfrage akzeptiert |
|
Das Schichtenmodell von CORBA:
| Schicht (Layer) | Erklõrung | ||
|---|---|---|---|
| Application | |||
| Skeletons /Stubs | Skeleton=vorgegebene Grundstruktur zur
Implementierung von Objektschnittstellen, deren Eigenschaften erst
wõhrend des Vorganges bekannt werden Stub=Lokale Funktion zur Weiterleitung eines Aufrufes |
||
| GIOP (General Inter-ORB Protocol) |
ESIOP (Environment-Specific Inter-ORB Protocol) |
GIOP: Hierher geh÷rt das IIOP (Internet Inter-ORB Protocol) das direkt mit TCP verbindet (und in den meisten Fõllen eine weitaus bessere Alternative zu HTTP bietet) | ESIOP: bisher existiert z.B. ein ESIOP f³r Open Groups DCE (Distributed Computing Environment): DCE-CIOP, welches DCE mit TCP verbindet. |
| Internet IOP | DCE-CIOP | ||
| TCP | |||
| IP | |||
| LANs/WANs | |||
CORBA-Schnittstellen und Objektinteraktion:
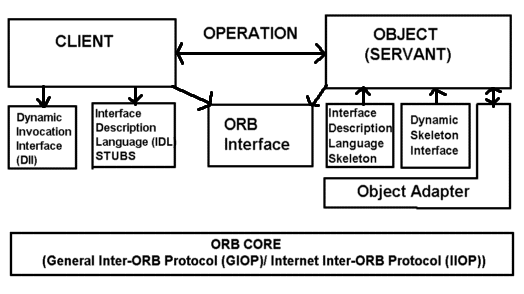
Abb.: CORBA-Schnittstellen und Objektinteraktion
Kurzerklõrungen:
Bisherige Anwender von CORBA:
"Computerwoche: Wie verwenden Unternehmen Corba in der Praxis?
Richard Soley, Chief Engineering Officer der OMG: Zur Zeit setzen viele Unternehmen Corba in einem oder zwei kleinen Projekten ein. Wenn dann das Know-how aufgebaut ist und entsprechende Tools verf³gbar sind, wird auch systemweit entwickelt. Vor allem in Japan und den USA sehen wir diesen Trend. Ein Beispiel ist etwa der US-Sender CNN, der Corba mittlerweile unternehmensweit einsetzt und alle m÷glichen Nachrichten in Text und Bild integriert. Die haben dort 350 000 Hits am Tag. [http://www.cnn.com/. -- Zugriff am 16.7.1999]
Computerwoche: Welches sind die Einsatzgebiete?
Soley: Normalerweise finden Sie Corba nur in gro▀en heterogenen Umgebungen. Anwenderbeispiele sind
- die Federal Aviation Association, [richtig: Administration. -- http://www.faa.gov/. -- Zugriff am 16.7.1999]
- die Deutsche Flugsicherheit [richtig: Flugsicherung. -- http://www.dfs.de/. -- Zugriff am 16.7.1999]
- oder der US-R³ckversicherer Lincoln National Reinsurance [http://www.lincolnre.com/. -- Zugriff am 16.7.1999]. Dieser nutzt Corba, um Daten aus dem Risiko-Management mit seinen Vertretern vor Ort auszutauschen, die die Informationen dann an Versicherungs-Unternehmen verkaufen.
....
Computerwoche: Wie ist die Akzeptanz von Corba in Deutschland?
Soley: Ich glaube, der deutsche Markt ist reservierter als andere. Die Anwender gehen vorsichtiger und organisierter an neue Techniken heran und m÷chten selbst bei Erfolg noch nicht ³ber ihre Projekte sprechen. Dies war anfangs in den USA genauso, weil die Unternehmen den Einsatz von Corba als strategisch ansehen."
[Corba 3.0 verspricht eine stabile Standardarchitektur : [Interview mit Richard Soley]. -- In: Computerwoche. -- 28/1999. -- S. 16.]
Beispiel einer CORBA Anwendung: LUIS BB -- Landesumweltinformationssystem Brandenburg
"Condat [http://www.condat.de/. -- Zugriff am 16.7.1999] recently saw the deployment of its new LUIS application in the federal state of Brandenburg, Germany, in a total of five locations. LUIS is an interactive system that was designed for the Ministry of the Environment, Nature Conservation and Spatial Planning of Brandenburg. As an integration platform, LUIS makes the current environmental information from Brandenburg available to all of the internal administrative system users, as well as to the general public, by means of the Internet. The information itself is stored in various locations and then updated locally within the various domain-specific applications. LUIS, as a distributed program system based on a broker architecture, is the foundation for the strategic development of the entire information technology system at the Ministry of the Environment.
When implementation of the LUIS project began in 1995, IONA's Orbix [http://www.iona.com/products/index.html. -- Zugriff am 16.7.1999] was the only available middleware product which provided the scalability, flexibility and robustness required to begin product development. Condat realised early on that CORBA marked the way forward for its new application. It saw that a CORBA-based architecture would provide the freedom necessary for developers building object oriented implementations. Using Orbix meant that there was only one communication protocol which alleviated Condat's need to install several drivers (ODBC for example) to construct a system which would eventually have to integrate heterogeneous information sources and systems. Orbix for HP-UX, Windows 3.1, Windows NT/95 and OrbixWeb provide the CORBA layer in Condat's LUIS application.
As an infrastructural system, LUIS delivers environmental information from a variety of existing systems which are connected using so-called äadapters". Current adapters include popular relational database systems such as Oracle, Informix and Access. It transports äpresentations" with the data that are based on standard desktop products like WordPerfect, Access, Excel and GIS-Systems (ESRIArcView). The system itself contains only metadata that is used to transparently determine some technical information to gain access to the underlying systems and, on the other hand, contains information which allows the user of the system to navigate and search in the services offered. The system uses IONA's Orbix, C++, OLE-Bridge and Java, and operates on several platforms including HP-UX and Windows 3.1, and Windows NT/95."
Quelle: http://www.omg.org/omg/organization.html. -- Zugriff am 13.7.1999
Die Entwicklung des CORBA-Standards:
Die folgende ▄bersicht soll einen Eindruck von der Komplexitõt von CORBA geben, ohne dass die Einzelheiten erklõrt werden:
| Jahr | Version | Features, die normiert werden |
|---|---|---|
| 1992 | Version 1.1. |
|
| 1995 | Version 2.0 |
|
| 1999 | Version 3.0 |
|
Vorlage der Tabelle: Corba 3.0 verspricht eine stabile Standardarchitektur. -- In: Computerwoche. -- 28/1999. -- S. 15.
Weiterf³hrende Ressourcen zu CORBA:
Yahoo Categories:
Organisationen:
Ressourcen in Printform:
Sayegh, Andreas <1964 - >: CORBA : Standard, Spezifikationen, Entwicklung. -- 2., aktualisierte und erweiterte Aufl. -- Beijing [u.a.] : O'Reilly, 1999. -- 153 S. : Ill. -- ISBN 3897211564. -- [Knapp und verstõndlich]. -- {Wenn Sie HIER klicken, k÷nnen Sie dieses Buch bei amazon.de bestellen}
"Computerwoche: Brauchen Corba-Anwender auch die Unterst³tzung des Common Object Model (COM) von Microsoft?
Soley: Wir w³rden COM niemals ignorieren. Schon 1995 ber³cksichtigten wir das Modell in den Spezifikationen, unterst³tzen mit Corba 3.= DCOM (Distributed COM) und werden uns auch mit COM+ beschõftigen, sobald es verf³gbar ist. Aus einer Corba-Komponente lõsst sich etwa problemlos eine COM-Beschreibung generieren. Bei DCOM gibt es allerdings kleine Unterschiede. Und auch Microsoft ignoriert uns nicht. Erst k³rzlich hat das Unternehmen mit der Ank³ndigung von Babylon [Codenamen f³r Microsoft's geplanten Enterprise Interoperability Server] eine Unterst³tzung des Internet-ORB Protocol (IIOP) bekanntgegeben. Das bedeutet, dass Corba ³berall zu Hause ist."
[Corba 3.0 verspricht eine stabile Standardarchitektur : [Interview mit Richard Soley]. -- In: Computerwoche. -- 28/1999. -- S. 16f.]
Weiterf³hrende Ressourcen zu DNA:
JPE wird von Sun's JavaSoft propagiert als Grundtechnologie f³r mehrstufige verteilte Systeme. JPE enthõlt sechs Grundtechnologien:
EJB -- Enterprise JavaBeans: erm÷glicht verteilte Komponenten zu bilden. Siehe: http://java.sun.com/products/ejb/. -- Zugriff am 16.7.1999
"Computerwoche: Viele sprechen davon, dass Corba und EJB verschmelzen k÷nnten. Und auch Sie sagten k³rzlich, dass Applikations-Server beides ben÷tigen.
Soley: Java-Entwickler werden feststellen, dass sie f³r die Entwicklung verteilter Systeme EJB und Corba brauchen. Schon heute kommuniziert EJB via Corba ³ber das Netz und nutzt den Corba Transaction Service. Bis auf Microsofts Transaction Server unterst³tzen inzwischen alle Applikations-Server EJB und Corba. Es ist deshalb die Aufgabe der OMG und von Sun, beide Architekturen in Gleichklang zu halten. Das hei▀t aber nicht, das EJB irgendwann einmal Cross-Language ist oder Corba nur noch Java unterst³tzt. Denn die Geschõftslogik wird nie ausschlie▀lich in EJB-Komponenten stecken, sondern auch in anders geschriebenen Programmen. Laut IDC gibt es beispielsweise immer noch drei Millionen Cobol-Programmierer."
[Corba 3.0 verspricht eine stabile Standardarchitektur : [Interview mit Richard Soley]. -- In: Computerwoche. -- 28/1999. -- S. 16.]
Java/RMI -- JavaÖ Remote Method Invocation Interface: erm÷glicht, JavaObjects und ihre Operationen auf anderen Computern aufzurufen. Siehe: http://java.sun.com/products/jdk/rmi/. -- Zugriff am 16.7.1999
JNDI -- JavaÖ Naming and Directory Interface: einheitliche Schnittstelle f³r inhomogene Naming und Directory Services. Siehe: http://java.sun.com/products/jndi/. -- Zugriff am 16.7.1999
JDBC -- JDBCÖ Data Access API: Die Java-Entsprechung zu ODBC. Siehe: http://java.sun.com/products/jdbc/. -- Zugriff am 16.7.1999
JTS -- JavaÖ Transaction Service: erm÷glicht Transaktionen (Alles-oder-Nichts-Operationen). Siehe: http://java.sun.com/products/jts/. -- Zugriff am 16.7.1999
JMS -- JavaÖ Message Service API: Siehe: http://java.sun.com/products/jms/. -- Zugriff am 16.7.1999
Die gelõufigste Methode f³r Anfrage und Eingabe an Datenbanken ist das HTML-Element <FORM>
|
Syntax |
Darstellung im Browser |
| <FORM>...</FORM>
mit den Unterelementen: <INPUT>
</SELECT> |
<FORM METHOD="POST" ACTION="--WEBBOT-SELF--">Eingabe
1<INPUT TYPE="submit" VALUE="Abschicken"
NAME="B1"><INPUT TYPE="reset" VALUE="Zur³cksetzen"
NAME="B2"></FORM>
Erscheint in Ihrem Browser so:
|
Wichtigste Attribute von <FORM>:
| Attribute | Beispiel |
|---|---|
| ACTION="URL des Programms, das die Daten weitervearbeitet" | <FORM ACTION="http://www.bigcompany.com/cgi-bin/post-query"
METHOD="POST">
bzw. mit relativer URL: <FORM ACTION="../cgi-bin/get-query" METHOD="GET"> |
| METHOD="GET"
bzw. METHOD="POST" |
s. oben |
Wichtigste Form Controls (Unterelemente von <FORM>):
| Element mit Attributen | Beispiel |
|---|---|
| <INPUT "TYPE="TEXT" NAME="Name des INPUT-Elements" SIZE="Gr÷▀e des Eingabefelds"> (f³r einzeilige Eingaben) |
<FORM METHOD="POST" ACTION="..."> <P>Vorname:<INPUT TYPE="TEXT" NAME="Vorname" SIZE="20"></P> <P>Name: <INPUT TYPE="TEXT" NAME="Name" SIZE="20"></P> </FORM> Erscheint in Ihrem Browser so:
|
| <INPUT "TYPE="PASSWORD" NAME="Name des INPUT-Elements" SIZE="Gr÷▀e des Eingabefelds"> (f³r Eingabe des Passworts) | <FORM METHOD="POST" ACTION="..."> <p>Passwort: <INPUT TYPE="PASSWORD" NAME="Passwort" SIZE="20"></p> </FORM> Erscheint in Ihrem Browser so: |
| <INPUT "TYPE="CHECKBOX" NAME="Name des INPUT-Elements"
VALUE="Bedeutung des Ankreuzens">
(Zur Auswahl mit Ankreuzen) |
<FORM METHOD="POST" ACTION="..."
NAME="Suche"><p> <INPUT TYPE="CHECKBOX" NAME="Monographien" VALUE="Monographien">Monographien<br> <INPUT TYPE="CHECKBOX" NAME="Zeitschriftenartikel" VALUE="Zeitschriftenartikel">Zeitschriftenartikel<br> <INPUT TYPE="CHECKBOX" NAME="Karten" VALUE="Karten">Karten<br> <INPUT TYPE="CHECKBOX" NAME="Filme" VALUE="Filme">Filme</p> </form> Erscheint in Ihrem Browser so: |
| <INPUT TYPE="RADIO" NAME="Name
des Buttons" VALUE="Bedeutung der Auswahl">
(zur Auswahl mit Radio Button) |
<FORM METHOD="POST" ACTION="..."
NAME="Anzeigeformat"><P> <INPUT TYPE="RADIO" VALUE="Kurzanzeige" CHECKED NAME="Anzeige">Kurzanzeige<br> <INPUT TYPE="RADIO" VALUE="Vollanzeige" NAME="Anzeige">Vollanzeige<br> <INPUT TYPE="RADIO" VALUE="Formatanzeige" NAME="Anzeige">Formatanzeige</p> </FORM> Erscheint in Ihrem Browser so: |
| <INPUT TYPE="SUBMIT" VALUE="Bedeutung
der Eingabe" NAME="Name des >INPUT>-Elements">
(zum Abschicken einer Eingabe) |
<FORM METHOD="POST" ACTION="..."> <p><INPUT TYPE="SUBMIT" VALUE="Abschicken" NAME="Eingabe"></p> </FORM> Erscheint in Ihrem Browser so: |
| <INPUT TYPE="RESET" VALUE="Reset
Form" NAME="Name des <INPUT>-Elements">
(zum L÷schen der Eingabe) |
<FORM METHOD="POST" ACTION="..."> <P><INPUT TYPE="TEXT" NAME="T1" SIZE="20"> <INPUT TYPE="RESET" value="Zur³cksetzen" NAME="B2"></P> </FORM> Erscheint in Ihrem Browser so: |
| <TEXTAREA ROWS="Anzahl der Zeilen"
COLS="Anzahl der Zeichen pro Zeile" NAME="Name
des TEXTAREA-Elements">Vorgabe</TEXTAREA>
(f³r mehrzeilige Eingaben) |
<FORM METHOD="POST" ACTION="..."> <p><TEXTAREA ROWS="5" NAME="Anfrage" COLS="20"></TEXTAREA></p> </FORM> Erscheint in Ihrem Browser so: |
<SELECT NAME="Name des SELECT-Elements">
</SELECT> (zur Auswahl aus einem Pull-Down-Men³) |
<FORM METHOD="POST" ACTION="..."> <p><SELECT SIZE="1" NAME="Suchstrategie"> <OPTION SELECTED>Alles</OPTION> <OPTION>Titel</OPTION> <OPTION>Autor</OPTION> <OPTION>Schlagwort</OPTION> </SELECT></p> </FORM> Erscheint in Ihrem Browser so: |
Online-Volltexte:
Yahoo Categories:
Virtual libraries:
Ressourcen in Printform:
Assfalg, Rolf ; Goebels, Udo ; Welter, Heinrich: Internet-Datenbanken : Konzepte, Modelle, Werkzeuge. -- Bonn : Addison-Wesley-Longman, 1998. -- ISBN 3827312302. -- [Gute ▄bersicht]. --{Wenn Sie HIER klicken, k÷nnen Sie dieses Buch bei amazon.de bestellen}.
Sheldon, Tom: Encyclopedia of networking. -- Berkeley [u.a.] : McGraw-Hill, ®1998. -- 1164 S. : Ill. + 1 CD-ROM. -- ISBN 0078823331. -- [Unentbehrlich!]. -- {Wenn Sie HIER klicken, k÷nnen Sie dieses Buch bei amazon.de bestellen}
Zum Nõchsten Kapitel:
Kapitel 16: Anhang : UNIX