mailto: payer@hbi-stuttgart.de
Zitierweise / cite as:
Payer, Margarete <1942 - >: Computervermittelte Kommunikation. -- Kapitel 13, 2,2,3: OSI-7 -- Application Layer. -- Teil 2, 2: Die Anwendungsschicht im Internet: WWW -- World Wide Web. -- 3. Web-Programmierung und Suchmaschinen. -- Fassung vom 10. Juli 1999. -- URL: http://www.payer.de/cmc/cmcs13223.htm. -- [Stichwort].
Erstmals publiziert: 1995
Überarbeitungen: 19. Juni 1997; 10. 7. 1999 [grundlegende Überarbeitung und Erweiterung]
Anlass: Lehrveranstaltungen an der HBI Stuttgart
©opyright: Dieser Text steht der Allgemeinheit zur Verfügung. Eine Verwertung in Publikationen, die über übliche Zitate hinausgeht, bedarf der ausdrücklichen Genehmigung der Verfasserin.
Zur Inhaltsübersicht von Margarete Payer: Computervermittelte Kommunikation.
Achtung: einige der Beispiele in diesem Kapitel werden nur mit MS Internet Explorer 5.0 richtig dargestellt!
Um das WWW nicht nur zum Publizieren nutzerunabhängiger Dokumente zu benutzen, ist es wichtig, programmierte Elemente einzubinden bzw. mit HTML-Dokumenten zu verbinden.
Skriptsprachen sind meist einfache Programmiersprachen. Programme in Skriptsprachen sind nicht umfangreich und müssen darum nicht vor dem Einsatz kompiliert werden. Für das Internet wichtige Skriptsprachen sind:
Wenn eine Skriptsprache fest in ein Anwendungsprogramm eingebaut ist, spricht man von einer Makrosprache.
Die Möglichkeiten der Interaktivität, die Webprogrammierung erlaubt, werden auch unter der Bezeichnung Dynamic HTML zusammengefasst.
Ausführlich zu einem Hauptproblem der Webprogrammierung, nämlich Datenbankaufbau, siehe Kapitel 15:
JavaScript ist eine einfache Programmiersprache für einfache, in HTML eingebundene Anwendungen, die clientseits ausgeführt werden (z.B. Reaktion auf einen Mausklick des Benutzers). JavaScript ist viel simpler als Java. JavaScript wird mit dem Tag
<SCRIPT LANGUAGE="JavaScript">Quelltext </SCRIPT>
in HTML-Dokumente eingefügt. Microsofts Variante von JavaScript ist JScript. Die bisher vorliegenden Anwendungen von JavaScript erscheinen nicht gerade überzeugend.
Weiterführende Ressourcen zu JavaScript:
Yahoo Categories:
Virtual Libraries:
WWW:
ECMA = European Computer Manufacturers Association . ECMAScript ist die von der ECMA herausgegebene Standard zu JavaScript. JavaScript und JScript gelten als Implementierungen von ECMAScript. ECMAScript findet noch kaum Unterstützung in Browsern!
VBScript = Visual Basic Script ist eine auf Microsofts Visual Basic beruhende Scriptsprache, mittels derer man kleine Programme, die clientseits ablaufen, direkt in die WebPage einbauen kann. Der Browser benötigt einen VBScript Interpreter (in MS Internet Explorer ab 3.0 enthalten, für Netscape ab 3.0 gibt es Zusatzmodul).
Einbindung in HTML:
<SCRIPT LANGUAGE="VBScript">Quelltext</SCRIPT>
Beispiel für VBScript:
Einfache clientseitige Plausibilitätsprüfung für Eingabe:
Versuchen Sie auch, unerlaubte Werte einzugeben!
Quelle des Beispiels: http://msdn.microsoft.com/scripting/default.htm?/scripting/vbscript/. -- Zugriff am 9.7.1999. -- [dort auch weitere Beispiele]
Das Script zu obigem Beispiel:
<SCRIPT LANGUAGE="VBScript">
<!--
Sub Button1_OnClick
Dim TheForm
Set TheForm = Document.ValidForm
If IsNumeric(TheForm.Text1.Value) Then
If TheForm.Text1.Value < 1 Or TheForm.Text1.Value > 10 Then
MsgBox "Please enter a number between 1 and 10."
Else
MsgBox "Thank you."
End If
Else
MsgBox "Please enter a numeric value."
End If
End Sub
-->
</SCRIPT>
Weiterführende Ressourcen zu VBScript:
Yahoo Categories:Java ist eine von Sun Microsystems ab 1990 entwickelte leistungsfähige Programmiersprache, die es auch erlaubt, in WWW-Ressourcen sogenannte Applets einzubauen, d.h. kleine Anwendungsprogramme, die auf dem Client ausgeführt werden. Applets werden mit dem Tag
<APPLET Attribute></APPLET>
in HTML-Dokumente eingefügt. In HTML 4.0 wird statt des <APPLET >-Elements das <OBJECT>-Element vorgeschrieben:
<OBJECT Attribute></OBJECT>
Beispiele von guten Applets siehe unten.
Java Beans sind in Java geschriebene austauschbare universelle Softwarekomponenten, die man miteinander verbinden und so Java-Programme baukastenmäßig zusammenbauen kann.
Weiterführende Ressourcen zu Java:
Yahoo Categories:
Virtual Libraries:
WWW:
FAQ:
Java FAQ Archives. -- URL: http://www-net.com/java/faq/. -- Zugriff am 28.6.1999
Ressourcen in Printform:
Java unleashed. -- Indianapolis, IN : Sams.net, ©1996. -- 958 S. : Ill. + 1 CD-ROMISBN 1-57521-049-5
Perl (practical Extraction and Report Language) wurde 1986 entwickelt. Obwohl Perl oft als Skriptsprache bezeichnet wird, ist Perl eine sehr leistungsfähige Programmiersprache. Perl-Programme werden vor der Ausführung in Perl-Code umgewandelt. Perl-Code wird aber nicht kompiliert, sondern interpretiert, läuft aber trotzdem relativ schnell. Da Perl sehr leistungsfähige Textverarbeitungs- und Dateifunktionen besitzt, eignet es sich gut, um HTML-Seiten bei interaktiven Anwendungen (z.B. Datenbankanbindungen) zu generieren. Man nützt Perl häufig, um CGI-Anwendungen zu programmieren (s.unten). Perl ist kostenlos verfügbar, aber leider nicht standardisiert, so dass Kompatibilitätsprobleme auftreten können.
Weiterführende Ressourcen zu Perl:
Yahoo Categories:
Virtual Libraries:
Organisationen:
PHP -- Hypertext Preprocessor ist eine in HTML einbettbare Scripting-Sprache. PHP wird entweder als CGI-Script ausgeführt oder es ist in die Web-Server-Software integriert. Voraussetzung für den Einsatz von PHP ist, daß der Server PHP unterstützt.
PHP kann in HTML eingefügt werden nach dem Muster folgenden Beispiels:
<?php echo $HTTP_USER_AGENT; ?>
(Dieses Script stellt fest und meldet, welchen Browser der Nutzer verwendet).
Weiterführende Ressourcen zu PHP:
Yahoo Categories:
Die Aufteilung der Programme auf Server oder Client ist kein Entweder-Oder, vielmehr sind alle möglichen Aufteilungen der Aufgaben möglich. Eine ganz einfache Aufgabenteilung ist z.B.:
Eine grobe, unsystematische
Übersicht über Mittel und Methoden der Web-Programmierung auf Seiten des Servers bzw. Clients gibt folgende Tabelle:
| Auf Seiten des Servers | Auf Seiten des Clients |
|---|---|
|
|
Weiterführende Ressourcen zu Programmierung auf Seiten des Servers:
Powell, Thomas A.: HTML : the complete reference. -- 2. ed. -- Berkeley [u.a.] : McGraw-Hill, ©1999. -- 1130 S. : Ill. -- ISBN 0072119772. -- S. 453 - 596 [Ausgezeichnete Einführung]. -- {Wenn Sie HIER klicken, können Sie dieses Buch bei amazon.de bestellen}. -- Sehr nützliche Auszüge dieses Buches sind online zugänglich: URL: http://www.htmlref.com/. -- Zugriff am 6.7.1999
Die Anforderungen des Client an den Server erledigt oft nicht der HTTP-Server selbst, sondern er übergibt sie zur Bearbeitung an andere Server-Programme, sog. gateway programs. Das Kommunikationsprotokoll zwischen HTTP-Server-Programm und gateway programs ist das CGI (Common Gateway Interface).
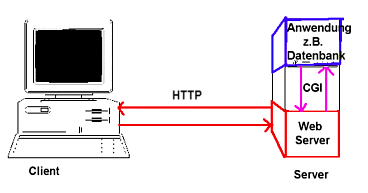
Abb.: Das Prinzip von CGI
CGI ist gegenüber Programmiersprachen neutral: CGI-Programme werden im allgemeinen in folgenden Programmiersprachen abgefasst:
| Betriebssystem | Programmiersprachen für CGI |
|---|---|
| UNIX | Perl, C, J++, Java, csh, ksh, sh, Python |
| Windows | Visual Basic, C, C++, Perl |
| MacIntosh | AppleScript, Perl, C, C++ |
Eine häufige Form der Übergabe von HTML an CGI ist über Formulare. Dazu dienen im Element <FORM> die Attribute ACTION und METHOD:
| Syntax | Beispiel |
|---|---|
| <FORM ACTION="URL des CGI-Scripts" METHOD="GET" bzw "POST">...</FORM> | <FORM ACTION=http://service.schlund.de/cgi-bin/ feedback/feedback.cgi METHOD=POST> ... </FORM> |
Beispiel eines CGI-Formulars:
Feedback:
Obiges Formular können Sie ausfüllen, wenn Sie "Senden" drücken, wird es per e-mail an die Verfasserin weitergeleitet.
MARKUP zu obigem CGI-Formular:
<FORM ACTION=http://service.schlund.de/cgi-bin/feedback/feedback.cgi METHOD=post>
<INPUT name=FBMAIL type=hidden value="payer@hbi-stuttgart.de">
<INPUT name=FBSUBJECT type=hidden value=Feedback>
Ihr Name:<INPUT name=name><BR>
Ihre e-mail-Adresse: <INPUT name=e-mail-Adresse size=36><BR>
<TEXTAREA cols=66 name=Nachricht rows=7></TEXTAREA><BR>
<INPUT type=submit value=Senden>
<INPUT type=reset value=Löschen>
</FORM>
Weiterführende Ressourcen zu CGI:
Yahoo Categories:
Virtual Libraries:
NSAPI (Netscape Server Application Programming Interface) und Microsofts ISAPI (Internet Server Application Interface) haben als Zweck, den Aufruf serverseitiger Programme zu beschleunigen. NSAPI- und ISAPI-Programme sind Plug-ins für Webserver. Sie sind meist in C oder C++ geschrieben. Da sie in den Webserver eingebunden sind, sind sie schwieriger zu schreiben als CGI: ein Fehler in einem solchen Programm kann den ganzen Webserver lahmlegen.
Parsed HTML ist Scripting auf Seiten des Servers. Das Prinzip ist:
Beispiele für Parsed HTML:
Die einfachste Form von Parsed HTML sind Server-Side Includes (SSI): Bestandteile, die der Server in HTML-Dokumente einfügt.
Beispiel eines einfachen Server-Side Include: Copyright-Vermerk
File copyright.htm:
<CENTER>©opyright: für nichtkommerzielle Zwecke frei. Für kommerzielle Zwecke ....</CENTER>
Um dies in andere Files einzufügen, fügt man in sie eine SSI-Anweisung ein, wie:
<!--#include file="copyright.htm">
Weiterführende Ressourcen zu Server-Side Includes:
Eine verbreitete Form von Parsed HTML ist Allaire's Cold Fusion™. Cold FusionMarkup Language (CFML) ist eine Markup Language, die HTML ähnelt. CFML erlaubt es, Datenbanken ins WWW einzubinden und so dynamische Web-Pages zu bilden.
Weiterführende Ressourcen zu Cold Fusion:
Microsofts Active Server Pages (ASP) ist eine Technologie, die es ermöglicht, in einer Skriptsprache (z.B. VBScript) entwickelte Programme auf dem Server auszuführen. Der Server erzeugt dann eine HTML-Seite, die er dem Client schickt. Web-Seiten, die auf ASP basieren, sind an der Erweiterung .asp erkennbar. Da ASP auf Seiten des Servers wirksam ist, ist ASP weitgehend unabhängig von der Art des Browsers. Eine Hauptanwendung von ASP ist die Einbindung von Datenbanken ins WWW.
Weiterführende Ressourcen zu ASP:
Programmierung auf Seiten des Client kann geschehen durch:
Programme, die auf Seiten des Client laufen, beinhalten immer Sicherheitsrisiken.
Plug-ins wurden von Netscape mit dem Navigator 2 eingeführt. Plug-ins sind kleine Hilfsprogramme, die in den Browser eingebunden werden und im Browser selbst ablaufen.
Plug-In-Anwendungen werden mit dem <OBJECT>-Element (früher: >EMBED>) in HTML eingebunden:
<EMBED SRC="URL" HEIGTH="..." WIDTH="...">
<OBJECT DATA="URL" TYPE="MIME-Type" HEIGHT="..." WIDTH="..." AUTOSTART="TRUE" bzw. "FALSE">
Schade Sie haben das entsprechende Plug-in nicht installiert</OBJECT>
Häufig verwendete Plug-ins sind z.B.:
Weiterführende Ressourcen zu Plug-Ins:
Yahoo Categories:
Virtual Libraries:
Java Applets sind kleine in Java geschriebene, kompilierte Programme, die in jedes Programm oder Betriebssystem eingebunden werden können, das Java Virtual Machine (JVM) unterstützt. Eingebettet werden sie in HTML mit dem <APPLET>-Element. Beispiele siehe im Folgenden.
Beispiel eines guten Applets:

Verfasser: D. Collomb
With the mouse
with Internet Explorer 4.0, by default the Menubar is embedded in the applet. |
MARKUP für dieses Applet:
<applet archive="Chemis3D.jar" code="Chemis3DApp.class" width="350" height="350">
<param name="model" value="DNA3.txt">
<param name="filetype" value="x-pdb">
<param name="display" value="ball">
Leider stellt Ihr Browser dieses Applet nicht dar
</applet>
Quelle: http://javaboutique.internet.com/Chemis3D/. -- Zugriff am 8.7.1999
Homepage von Chemis3D: http://members.xoom.com/Chemis/Chemis3D.htm. -- Zugriff am 9.7.1999
Ein weiteres Beispiel eines guten Applet:
Glossar zu Java (das Applet ist Freeware):
Eingebunden mit:
<APPLET CODE="glossary.class" WIDTH="440" HEIGHT="340">
sowie sehr vielen PARAMETER-Werten, z.B.:
<PARAM NAME=
"t18" VALUE="3 |/products/jndi/index.html |Java(TM) Naming and Directory Interface(TM) - |Java Naming and Directory Interface - |JNDI | "><PARAM NAME=
"d18" VALUE=" Provides uniform, industry-standard, seamless connectivity from the Java platform to business information assets, thus allowing developers to deliver Java applications with unified access to multiple naming and directory services across the enterprise. ">
Quelle des Applet: http://java.sun.com/openstudio/applets/glossary.html. -- Zugriff am 8.7.1999
Weiterführende Ressourcen zu Java Applets:
Yahoo Categories:
ActiveX ist Microsofts Antwort auf Java. Das Prinzip ist die Anwendung von OLE (Object Linking and Embedding) aufs WWW. Es ermöglicht ähnlich wie Java die Einbindung von Applikationen, die clientseits laufen. ActiveX ermöglicht es auch, Dokumente von Microsoft-Anwendungen wie Excel oder MS Word über einen WebBrowser zu betrachten. ActiveX Controls (entsprechen Netscape's Plug In's) werden mit dem Tag
<OBJECT Attribute></OBJECT>
in ein HTML-Dokument eingebunden.
Beispiel einer ActiveX-Control:
(Das Menü könnte z.B. Links herstellen)
Weiterführende Ressourcen zu ActiveX:
Yahoo Categories:
Virtual Libraries:
Alle bisher genannten Programmiermethoden für das WWW nutzen das WWW nicht eigentlich als Web, als Geflecht unzähliger Ressourcen: sie verwenden immer eine Form eines zweiseitigen Client-Server-Modells. Wirkliches Web-Programming dagegen würde es ermöglichen, für den Nutzer transparent (d.h. ohne dass er es merkt) zahlreiche Ressourcen zu nutzen und zu einer einzigen Ressource zusammenzufassen: z.B. mit Hilfe unterschiedlicher Datenbanken und Datenbearbeitungsprogrammen die spezifische Lösung bzw. Antwort, die der Nutzer braucht herzustellen. Dieser Aufgabe widmet sich Distributed Programming. Echtes Distributed Programming steckt allerdings noch in den Kinderschuhen.
RMI ist ein erster Schritt in Richtung von echtem Distributed Programming. Es ist eine Schnittstelle, die es Java-Anwendungen (Objekten) erlaubt, Java-Programmen, die auf andern Java Virtual Machines laufen, Teilaufträge (z.B. Berechnungen) zu erteilen.
Weiterführende Ressourcen zu RMI:
CORBA wurde 1991 von der OMG (Object Management Group) als Spezifikation ihrer Object Management Architecture (OMA) vorgestellt. Es ist eine Spezifikation, die die Definition der Schnittstellen in verteilten Systemen sowie die Kommunikation zwischen diesen Schnittstellen ermöglicht. CORBA ist systemunabhängig und auch nicht an eine bestimmte Programmiersprache gebunden.
Ausführlicher zu CORBA in Kapitel 15: Datenbanken im Internet
Weiterführende Ressourcen zu CORBA:
Yahoo Categories:
DCOM ist Microsofts Versuch einer Lösung für verteilte Komponenten zur Lösung eines Problems. Einzelheiten siehe bei den weiterführenden Ressourcen.
Weiterführende Ressourcen zu DCOM:
| "... die Existenz einer Webseite ist lediglich ein
Indiz für technische Fertigkeiten, mehr nicht -- und das ist wenig
genug. Obendrein ist es ein Kinderspiel, einer Webseite ein seriöses
Aussehen zu geben, ohne dass auch nur eine einzige seriöse Meldung zu
finden wäre. Was es außerhalb des Netzes noch nicht einmal bis zum
Flugblatt schafft, kann im Internet ohne weiteres als weltweites
Nachrichtenmagazin auftreten."
[Damschke, Giesbert: Von einer Fallgrube in die andere. -- In: NZZ. -- Internationale Ausgabe. -- 9.7.1999. -- S. 49] |
Die folgenden Kriterien gelten vor allem für Web-Publikationen im wissenschaftlichen Bereich.
Ausführlich dazu:
Payer, Margarete <1942 - >: Wie kann man die Qualität von Internetressourcen für den wissenschaftlichen Bereich beurteilen? : Hinterfragung ausgewählter Vorschläge ; Vortrag am 11. Juni 97, HBI Stuttgart. -- Fassung vom 9. Juni 1997. -- URL: http://machno.hbi-stuttgart.de/~payer/infoq.html
Zur Platform for Internet Content Selection (PICS), einem Bewertungssystem zum Jugendschutz siehe:
http://dir.yahoo.com/Computers_and_Internet/Information_and_Documentation/Metadata/Platform_for_Internet_Content_Selection__PICS_/. -- Zugriff am 30.6.1999
Formale Gesichtspunkte
Bezüglich der Zitierbarkeit:
Publiziert man selbst im Internet, so sollte man
unbedingt folgende Angaben zu Beginn des Textes machen
z.B.
Die Ressourcen-Angabe erfolgt in folgender Form:
z.B.
|
Bezüglich der Verwendbarkeit:
Dieser Teil sollte möglichst als normierte Metadaten dem HEAD des Dokuments hinzugefügt werden, dann könnte man mit automatischen Suchmaschinen schon eine gute Vorauswahl treffen.
Inhaltliche Gesichtspunkte
Gesichtspunkte der Darbietung
bezüglich des äußeren Erscheinungsbildes:
bezüglich der Semantik:
bezüglich der Benutzerfreundlichkeit:
Weiterführende Ressourcen zur Gestaltung guter Web-Seiten:
Ressourcen in Printform:
Tufte, Edward Rolf: The visual display of quantitative information. -- Cheshire : Graphics Press, ©1983. -- 156 S. : Ill. -- ISBN 096139210X. -- {Wenn Sie HIER klicken, können Sie dieses Buch bei amazon.de bestellen}
Tufte, Edward Rolf: Envisioning information : narratives of space and time. -- Cheshire : Graphics Press, ©1990. -- 126 S. : Ill. -- ISBN 0961392118. -- {Wenn Sie HIER klicken, können Sie dieses Buch bei amazon.de bestellen}
Tufte, Edward Rolf: Visual explanations : images and quantities, evidence and narrative. -- Cheshire : Graphics Press, ©1997. -- 156 S. : Ill. -- ISBN 0961392126
. -- {Wenn Sie HIER klicken, können Sie dieses Buch bei amazon.de bestellen}[Diese Trilogie von E. R. Tufte ist ein ausgezeichnetes Gegenmittel gegen die dümmliche Verwendung von Graphik und Pseudodesign, die die Hohlheit des Inhalts verbergen soll. Tufte's Bücher sind voll von positiven und negativen Beispielen, an denen man sehr viel lernen kann.]
Wie findet man etwas in WWW?
Da im Gebiet der Erschließung des WWW beinahe täglich etwas Neues erscheint, sei hier als erstklassiger Einstieg in die Information über Web Search Tools nur genannt:
Search Engine Watch. -- URL: http://www.searchenginewatch.com/. -- Zugriff am 10.7.1999. -- [Im freien Bereich gute Informationen, im Subskriptionsbereich (49 US$/Jahr) ausführliche Materialien, z.B. ausgezeichnete Texte "How N.N. works" zu den einzelnen Search Engines]
Yahoo Categories:
Virtual Libraries:
Man unterscheidet:
Eine Search Engine hat folgende Komponenten:
Weiterführende Ressourcen zu Robots, Spiders usw.
Yahoo Categories:
Virtual Libraries:
Zeittafel zu Suchmaschinen und Directories:
Die folgende Zeittafel zeigt wie kurz die Geschichte der Internet-Suchmaschinen und -Directories ist. Es ist deshalb nicht verwunderlich, dass Suche im Internet noch alles andere als optimal ist.
[Zugriff auf alle Links am 10.7.1999]
1990
Archie wird von einem Studenten der McGill University, Montreal, Kanada als Suchwerkzeug für FTP-Server entwickelt (zu Archie siehe Kapitel 13,2,1: Die Anwendungsschicht im Internet (ohne WWW)
1993
Veronica wird von der University of Nevada System Computing Services Group als Suchwerkzeug für Gopher entwickelt. Als weiteres Gopher-Suchwerkzeug wird Jughead entwickelt
Für das WW entwickelt Matthew Gray, ein MIT-Student den ersten Robot: World Wide Web Wanderer. Mit dem Wanderer wird Wandex, die erste WWW-Datenbank erstellt
Ab Februar 1993 entwickeln sechs Undergraduates der Stanford-University Architext, den Vorläufer von Excite
Im Oktober 1993 entwickelt Martijn Koster einen Archie-ähnlichen Index zum WWW: ALIWEB
Dezember 1993: drei Robots-gestützte Search Engines werden eröffnet: JumpStation,, World Wide Web Worm, RBSE-Spider
1994
Januar 1994: EINet Galaxy startet: das erste Web-Directory
April 1994: WebCrawler startet: die erste Full Text Search Engine im Internet
May 1994: Lycos startet: von Michael Mauldin von der Carnegie Mellon University entwickelt
Ende 1994: Yahoo!, von zwei Doktoranden der Stanford-University entwickelt, startet
1995
Infoseek startet
Ein Student der University of Washington entwickelt MetaCrawler, eine Meta Search Engine, d.h. eine Search Engine, die Anfragen an mehrere der großen Search Engines gleichzeitig stellt. MetaCrawler startet im Juli 1995
Dezember 1995: DEC's AltaVista geht online, um die Leistungsfähigkeit von DEC's Alpha Computer zu beweisen. AltaVista bringt auch in den Suchmöglichkeiten viele Innovationen
1996
Mai 1996: Inktomi's HotBot geht online. Wird bald von Wired Magazine übernommen.
1997
März 1997: HotBot setzt das SmartCrawl-System ein: damit können bis zu 10 Millionen Web-Pages pro Woche indiziert werden (vergleichbare Systeme schaffen 3 Millionen Web Pages pro Woche)
Oktober 1997: AltaVista umfaßt 100 Millionen Web-Pages, damit ist es die größte Search Engine im WWW
November 1997: HotBot überrundet AltaVista mit 110 Millionen Web-Pages
1998
Januar 1998: AltaVista startet automatischen Übersetzungsdienst mit der Software SYSTRAN: eine unerschöpfliche Quelle unfreiwilligen Humors
Mai 1998: AltaVista startet Chinesisch, Japanisch, Koreanisch
GoTo startet: erste Suchmaschine, die Platzierungen nach Bezahlung vornimmt: je mehr man zahlt, um so weiter oben in der Suchergebnisliste wird man platziert
1999
April 1999: AltaVista beginnt Platzierungen zu verkaufen
[Die vielen geschäftlichen Transaktionen, Verkäufe und Verbindungen werden in obiger Zeittafel nicht erwähnt: sie sind aber mindestens ebenso wichtig wie die technischen Entwicklungen.]
Die Zukunft von Suchmaschinen:
Eine ganz wichtige Zukunftsperspektive für die Erschließung des Internets und für Suchmaschinen sind die Markierungsmöglichkeiten, die XML bietet (s. dazu Kapitel 12,2: Presentation Layer, Teil II). Wenn es den dafür Kompetenten, d.h. vor allem den Bibliothekaren, gelingen würde, hier einheitliche, aber auch leicht anwendbare Normen zu schaffen, dann wäre ein entscheidender Schritt in Richtung Global Village Library getan.
Auch andere Wege werden versucht, vor allem im Bereich der Künstlichen Intelligenz. Nach der Ernüchterung mit Künstlicher Intelligenz nach vollmundigen Ankündigungen ist hier aber wohl eher gesunde Skepsis angebracht:
"Die elektronischen Medien stellen uns eine immer unübersichtlicher werdende Flut jederzeit abrufbarer Informationen zur Verfügung. Allein im Internet existieren Hunderte Millionen von WWW-Seiten und Usenet-Artikeln. Immense Textsammlungen finden sich in elektronischer Form auch in Bibliotheken, in Nachrichtenredaktionen oder auf Patentämtern. Um spezifische Informationen aus solchen Sammlungen zu extrahieren, gibt es Suchprogramme. Sie erfordern die Angabe von Schlüsselwörtern oder freien Textstrings, die meist zusätzlich mittels Boolescher Operatoren zu komplexeren Suchbegriffen verknüpft werden können.
Solche Maschinen erlauben zwar das gezielte Suchen nach bestimmten Inhalten, sie liefern jedoch keine allgemeine Übersicht über das vorhandene Material und eignen sich deshalb schlecht für das Auskundschaften. Das Internet ist damit vergleichbar mit einem dicken Wälzer, der wohl ein Sachverzeichnis, aber weder Titel noch Inhaltsverzeichnis hat. Wie soll man sich also darin zurechtfinden, wie kann man Unbekanntes entdecken oder Zusammenhängen auf die Spur kommen?
Übersicht schaffen könnten die sogenannten selbstorganisierenden Karten (Self-Organizing Maps oder SOM), die große Mengen von Daten nach ihrer Ähnlichkeit zu ordnen vermögen. Es handelt sich um einen Typ von künstlichen neuronalen Netzen, der seit den frühen achtziger Jahren von Prof. Teuvo Kohonen. am Neural Network Research Centre der Helsinki University of Technology entwickelt worden ist. SOM werden heute mit Erfolg insbesondere in der Industrie (z. B. Papier- und Stahlherstellung) und in der Medizin (z. B. Mustererkennung in EEG und EKG) eingesetzt. ...
Erst die praktische Anwendung auf große Dokumentensammlungen kann zeigen, was die Websom-Methode taugt. Die Gruppe von Prof. Kohonen hat deshalb eine Browser-Schnittstelle geschaffen und stellt diese auch gleich über das Internet der Öffentlichkeit zur Verfügung. Alle Interessierten können so das System selber auf die Probe stellen und über die Internet-Adresse http://websom.hut.fi/websom/ [Zugriff am 10.7.1999] verschiedene Demos aufrufen. Einer Demo liegt beispielsweise eine spezialisierte Sammlung von 12 000 Artikeln aus der Usenet-Diskussionsgruppe «comp.ai.neural-nets» zugrunde. Dies sind alle Diskussionsbeiträge zum Thema neuronale Netze, die zwischen Juni 1995 und März 1997 erschienen sind. Eine andere Demo zeigt, dass die Methode selbst für ein sehr breites Spektrum von Themen funktioniert: Sie basiert auf dem Material von 83 verschiedenen Usenet-Diskussionsgruppen mit insgesamt über einer Million Beiträgen! Wahrlich ein harter Test, denn bekanntlich sind solche Texte oft recht salopp geschrieben und enthalten wenig präzise Information. Außerdem sind umgangssprachliche Ausdrücke und Rechtschreibefehler häufig, was die automatische Verarbeitung zusätzlich erschwert.
Die Benutzerschnittstelle kennt vier zunehmend detaillierte Ebenen: Die oberste Ebene enthält die graphische Darstellung der gesamten Dokumentenkarte. Sie gibt dem Benutzer eine allgemeine Übersicht über die am häufigsten vorkommenden Themen. Die Färbung der Karte gibt außerdem an, wie viele Beiträge im betreffenden Gebiet existieren. Die nächste Ebene zeigt einen gezoomten Ausschnitt eines ausgewählten Gebiets. Sie erlaubt eine genauere Recherche zu einem bestimmten Thema. Durch Anklicken eines bestimmten Knotens auf dieser Darstellung kommt man auf die dritte Ebene, wo die Titel der darin enthaltenen Artikel aufgelistet werden. Durch An klicken eines bestimmten Titels schließlich wird der Inhalt des betreffenden Beitrags angezeigt."
[Nef, Christian: Neue Pfadfinder für den Cyberspace : Websom -- mit neuronalen Netzen Dokumente ordnen. -- In: NZZ. -- Internationale Ausgabe. -- 9.2.1999. -- S: B 7.]
Zum nächsten Kapitel:
Kapitel 13,2,3: USENET