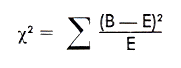Zitierweise / cite as:
Payer, Alois <1944 - >: Kauţilîya-arthaśâstra : eine Einführung. -- 3. Quellenscheidung mit Chi-Quadrat: T. R. Trautmann. -- Fassung vom 2002-11-10. -- URL: http://www.payer.de/kautilya/kautilya03.htm. -- [Stichwort].
Erstmals publiziert: 2002-11-10
Überarbeitungen:
Anlass: Lehrveranstaltung WS 2002/03
Unterrichtsmaterialien (gemäß § 46 (1) UrhG)
©opyright: Dieser Text steht der Allgemeinheit zur Verfügung. Eine Verwertung in Publikationen, die über übliche Zitate hinausgeht, bedarf der ausdrücklichen Genehmigung der Herausgeberin.
Dieser Teil ist ein Kapitel von:
Payer, Alois <1944 - >: Kauţilîya-arthaśâstra : eine Einführung. -- 1. Einleitung. -- URL: http://www.payer.de/kautilya/kautilya01.htm.
Dieser Text ist Teil der Abteilung Sanskrit von Tüpfli's Global Village Library.
Grundlage:
Trautmann, Thomas R.: Kautilya and the Arthasastra : a statistical investigation of the authorship and evolution of the text / Thomas R. Trautmann. With a preface by A. L. Basham. -- Leiden : Brill, 1971. -- XVIII, 227 S. -- Zugleich: Dissertation, Univ. of London, 1968

Abb.: Thomas R. Trautmann [Bildquelle:
http://www.lsa.umich.edu/humin/staff/index.html. -- Zugriff am 2002-11-07]
Thomas R. Trautmann, Ph.D., ist Professor for History & Anthropology an der University of Michigan, Ann Arbor:
"Trautmann holds the Marshall Sahlins Collegiate Professorship in recognition of his scholarship, and is editor of the Journal for Comparative Studies in Society and History. He holds a BA in Anthropology from Beloit College and a PhD in History from the University of London, where he specialized in the history of ancient India. He has written widely on India, mostly at the intersection of history and anthropology, and on the history of anthropological thought. Specific areas of interest include kinship, ideas of time, and the history of ideas about race and language." [Quelle: http://www.lsa.umich.edu/humin/staff/index.html. -- Zugriff am 2002-11-07]
Trautmann hat außer dem Kautilya-Buch folgende Monographien verfasst:
Er ist Herausgeber folgender Monographien:
Thomas R. Trautmann wendet in seiner Dissertation statistische Methoden der Autorenschaftsanalyse auf Kautilya an.
Er versucht es dabei mit drei Testgrößen:
Bei den Wörtern folgt Trautmann
Morton, A. Q. (Andrew Queen): The authorship of Greek prose. -- In: Journal of the Royal Statistiocal Society. -- Series A. -- 128 (1965). -- S. 169 - 233
Morton hatte in seinem Versuch, die echten paulinischen Briefe von den pseudopaulinischen zu scheiden, die Häufigkeitsverteilungen (Vorkommen pro Satz) der häufigen Wörter
als Testgrößen verwendet.
Für Trautmann waren bei der Auswahl der Testwörter folgende Kriterien ausschlaggebend (Trautmann, T. R., 1971, S. 91 - 92):
Mit der Auswahl häufiger -- und damit als solcher nicht spezifischer -- Wörter unterscheidet sich Trautmann z.B. von Alvar Ellegård, der noch 1962 geschrieben hat:
"The words most frequently used in the language -- articles, prepositions, conjunctions, and pronouns as well as the commonest verbs, nouns, adjectives and adverbs -- are necessarily about equally frequent in all texts, whoever the author. And this means in effect that the large majority of the positively or negatively distinctive words will belong to the frequency ranges below 0.0001, or one per ten thousand."
[Ellegård, Alvar: A statistical method for determining authorship: the Junius letters, 1769-1772. -- [Göteborg, 1962]. -- S. 15 - 16 (Zitiert bei Trautmann, T. R.., 1971, S. 79 - 80)]
Die Verwendung allgemein üblicher Wörter als Testgrößen hat auch den Vorteil, dass ihre Verteilung weitgehend unabhängig ist vom behandelten Gegenstand und nur durch die Sprach- oder Schreibgewohnheiten des Autors bedingt ist (Trautmann, T. R., 1971, S. 80)
Trautmann beschränkt sich dann de facto auf Indeklinabilia (Trautmann, T. R., 1971, S. 94), weil diese nach seinen -- (Trautmann, T. R., 1971, S. 102 beschriebenen) -- Methoden am leichtesten zu erheben waren.
Trautmann sieht das Problem, das diese Forderung mit sich bringt:
"We can never prove the proposition that a given word is always evenly distributed within authors ... We can, from a preliminary word list, eliminate those which are unevenly distributed in any one of as many authors as we include in our control material ..." (Trautmann, T. R., 1971, S. 92)
Eine Pilot-Studie an vier Prosatexten zu je 300 zusammenhängenden (bzw. durch Verse unterbrochenen) Sätzen erschien ermutigend für die Verwendung solcher Wörter als Testgrößen.
Bei ca und vâ ergibt der Chi-Quadrat-Test signifikante Unterschiede in der Verteilung zwischen dem zweiten Buch Kautilyas einerseits und dem 7. und 9. Buch andrerseits. (Trautmann, T. R., 1971, S. 82 - 88). Diese Unterschiede werden in den folgenden Graphiken, die ich aufgrund von Trautmann's zahlen erstellt habe, sehr augenfällig:
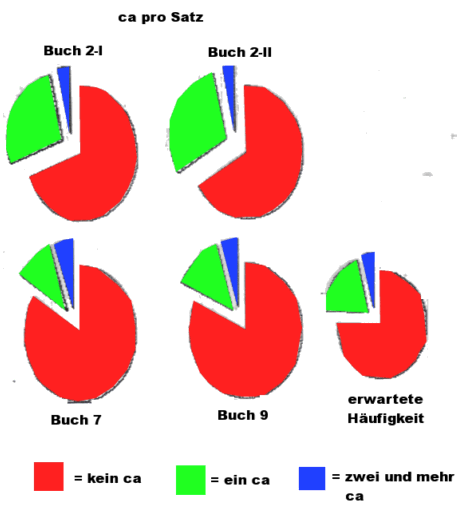
Abb.: Verteilung von ca pro Satz in Stichproben von Prosatexten aus Kautilya 2,
7, 9 sowie der erwartete Verteilung bei zufälliger Verteilung des ca
(Datengrundlage: Trautmann, T. R., 1971, Tab. 3.5,
S. 85)
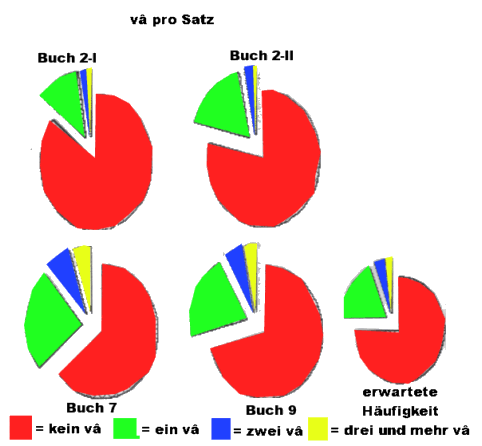
Abb.: Verteilung von vâ pro Satz in Stichproben von Prosatexten aus Kautilya 2,
7, 9 sowie erwartete Verteilung bei zufälliger Verteilung des vâ
(Datengrundlage: Trautmann, T. R., 1971, Tab. 3.4,
S. 84)
Abb.: Verhältnis von ca und vâ in Stichproben von Prosatexten aus Kautilya 2, 7,
9 (Datengrundlage: Trautmann, T. R., 1971, Tab. 3.1
und 3.2, S. 83)
So augenfällig die Unterschiede sind, so muss doch zunächst noch die alternative Hypothese ausgeschlossen werden, dass die Unterschiede nicht auf einen unterschiedliche Autoren zurückzuführen ist, sondern auf den unterschiedlichen Kontext. Deshalb versucht Trautmann zunächst diese Hypothese durch einen Test an Werken mit bekannter Autorschaft zu testen. Dabei sollen diese Werke ein breites Spektrum von Inhalten umfassen, um Kontextabhängigkeit auszuschließen. (Trautmann, T. R., 1971, S. 89).
Aus einer vorläufigen Liste von 32 Indeklinabilia (Trautmann, T. R., 1971, S. 95) bleiben nach entsprechenden Tests (Trautmann, T. R., 1971, S. 104 - 114; Tabellen: S. 188 - 208) folgende fünf als häufig, kontextunabhängig und diskriminierend übrig:
eva
evam
ca
tatra
vâ
Um den Schwierigkeiten zu entgehen, die sich ergeben, wenn man Sätze als Bezugsgrößen nimmt (Sätze sind in Sanskrittexten oft nicht eindeutig abgrenzbar) (Trautmann, T. R., 1971, S. 100 - 104), wählte Trautmann als Bezugsgröße für seine folgenden Untersuchungen feste Wortblöcke aus je 20 Wörtern, d.h. er zählte die Häufigkeitsverteilungen: Häufigkeit des Vorkommens des betreffenden Wortes pro Block aus 20 Wörtern.
Trautmann vertritt die Hypothese, dass
"there is excellent reason to regard
- the division into chapters,
- the terminal verses,
- the entirety of Artha´sâstra 1.1 with its table of contents and its enumeration of book, chapter, topic and ´sloka totals
- and, since it refers to the first chapter, Book 15 (tantrayukti),
as the work of a later, tidying and organizing hand, reworking a text already divided by books and topics, and already possessing an adequate introduction in Artha´sâstra 1.2." (Trautmann, T. R., 1971, S. 75).
Dieser spätere Text eignet sich aber nicht für einen statistischen Vergleich mit den übrigen Teilen des Kautilya, da es einerseits Verse sind, andrerseits die Prosastücke zu kurz sind für eine statistische Prüfung. So kann Trautmann nicht prüfen, ob dieser von ihm angenommene Endredaktor identisch ist mit dem Verfasser anderer Teile des Kautilya (Trautmann, T. R., 1971, S. 114). Deshalb prüft Trautmann statistisch nur Kautilya 1.2 bis Kautilya 14.
Um die statistische Signifikanz eventueller Unterschiede beurteilen zu können, wendet Trautmann den Chi-Quadrat-Test an.
Der Chi-Quadrat-Test ist ein einfacher Signifikanztest für Fälle, in denen Beobachtungen Klassen zugeordnet und als Häufigkeiten behandelt werden können. Dabei wird der Unterschied zwischen den beobachteten und erwarteten Häufigkeiten darauf hin geprüft, mit welcher Wahrscheinlichkeit ein solcher Unterschied rein zufällig zustande kommt. Je nach der Höhe des Anspruchs an Unwahrscheinlichkeit (Signifikanzniveau), wird man die Nullhypothese verwerfen oder beibehalten.
Häufigkeiten, die nach dem Chi-Quadrat-Test beurteilt werden können, kann man in einer Tabelle nach Zeilen und Spalten entsprechend zu folgendem einfachen Beispiel tabulieren:
| Anzahl der positiven Fälle | Anzahl der negativen Fälle | insgesamt | |
|---|---|---|---|
| Behandlungsgruppe | 45 | 8 | 53 |
| Kontrollgruppe | 18 | 37 | 55 |
| insgesamt | 63 | 45 | 108 |
Die Tafel unseres Beispiels ist eine zwei-mal-zwei-Tafel (Vierfeldertafel), da die Beobachtungen auf vier Felder verteilt werden. Analog gibt es drei-mal-drei-Felder-Tafeln usw.
Nullhypothese (d.h. Hypothese mit der Annahme, dass zwischen Behandlungsgruppe und Kontrollgruppe kein signifikanter Unterschied besteht ) ist: Die Verteilung der Häufigkeiten für jede Zeile der Tabelle ist nicht signifikant verschieden von der Verteilung der Häufigkeiten der Randsummen der Zeilen, d.h. mit anderen Worten: Behandlungsgruppe und Kontrollgruppe sind bezüglich der untersuchten Merkmale nicht verschieden, sondern gehören beide derselben Menge an.
Zur Durchführung des Chi-Quadrat-Tests muss man die Anzahl der Freiheitsgrade bestimmen, d.h. die Anzahl der Felder mit beobachteten Häufigkeiten, für die man eine unter Voraussetzung der Nullhypothese erwartete Häufigkeit berechnen muss. Die Zahl der Freiheitsgrade ist immer Geringer als die Zahl der Beobachtungsfelder, da z.B. in unserem Beispiel, wenn die erwartete Häufigkeit für ein Feld errechnet ist, die Werte der übrigen Felder durch Subtraktion von der Gesamtzahl der Fälle bestimmen kann.
In unserem Fall ergibt sich die erwartete Häufigkeit in Feld 1 aus folgender Proportionsgleichung: 63 : 108 = x : 53, d.h. x = (63 : 108)x53 = 30,9. Tragen wir diesen Wert in Feld 1, können wir die übrigen erwarteten Häufigkeiten durch Subtraktion errechnen. Unsere Tafel hat also einen Freiheitsgrad.
| Anzahl der positiven Fälle | Anzahl der negativen Fälle | insgesamt | |
|---|---|---|---|
| Behandlungsgruppe | 45 / erwartet: 30,9 | 8 / erwartet: 53-30,9= 22,1 | 53 |
| Kontrollgruppe | 18 / erwartet: 63-30,9 = 32,1 | 37 / erwartet: 55-32,1 = 22,9 | 55 |
| insgesamt | 63 | 45 | 108 |
Allgemein ist die Anzahl der Freiheitsgrade (Spaltenzahl - 1) x (Zeilenzahl - 1), also z.B. für eine zwei-mal-drei-Tafel (2 - 1)x(3 - 1)=1x2= 2 Freiheitsgrade.
Zur Bestimmung von Chi-Quadrat (χ²) bildet man die Differenzen zwischen beobachteten und erwarteten Häufigkeiten für jedes Beobachtungsfeld und quadriert diesen Wert, den so gewonnenen Wert teilt man durch die erwartete Häufigkeit. Dann bildet man die Summe all dieser Werte, diese Summe nennt man Chi-Quadrat.
| Chi-Quadrat = Summe von [(Beobachtungswert - Erwartungswert)² : Erwartungswert] |
|
|
In unserem Beispiel:
χ² = (45 - 30,9)²/30,9 + (8 - 22,1)²/22,1 + (18 - 32,1)²/32,1 + (37 - 22,9)²/22,9 = 6,43 + 9,00 + 6,19 + 8,68 = 30,30
[In der Praxis verwendet man heute ein Statistikprogramm, das alle nach der Eingabe der beobachteten Häufigkeiten alle weiteren Berechnungen automatisch durchführt. Sehr praktisch ist der Web Chi Square Calculator. -- URL: http://www.georgetown.edu/cball/webtools/web_chi.html. -- Zugriff am 2002-11-05 ].
Diesen χ²-Wert vergleicht man (oder das Statistikprogramm) mit einer Tafel der χ²-Verteilungen.
Ein Ausschnitt aus einer solchen Tafel:
| Die Wahrscheinlichkeit, unter der Nullhypothese ein χ² zu erhalten, das größer oder gleich dem eingetragenen Tabellenwert ist | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Anzahl der Freiheitsgrade (df) |
0,99 | 0,95 | 0,90 | 0,70 | 0,50 | 0,30 | 0,10 | 0,05 | 0,01 | 0,001 |
| 1 | 0,00016 | 0,0039 | 0,016 | 0,15 | 0,46 | 1,07 | 2,71 | 3,84 | 6,64 | 10,83 |
| 2 | 0,02 | 0,10 | 0,21 | 0,71 | 1,39 | 2,41 | 4,60 | 5,99 | 9,21 | 13,82 |
| 3 | 0,12 | 0,35 | 0,58 | 1,42 | 2,37 | 3,66 | 6,25 | 7,82 | 11,34 | 16,27 |
| 4 | 0,30 | 0,71 | 1,06 | 2,20 | 3,36 | 4,88 | 7,78 | 9,49 | 13,28 | 18,46 |
Da unser Beispiel einen Freiheitsgrad hat, schauen wir in der ersten Zeile nach. Dort stellen wir fest, dass der nächste angegebene Wert, der kleiner als 30,3 ist, nämlich 10,83, ein χ²-Wert ist, der eine Wahrscheinlichkeit von 0,001 hat, d.h. der zufällig im Durchschnitt ein mal in 1000 Fällen vorkommt. Wir laufen also ein geringes Risiko, wenn wir die Nullhypothese verwerfen: wenn wir 1000 mal unter ähnlichen Bedingungen die Nullhypothese verwerfen, irren wir uns im Durchschnitt ein einziges mal.
[Das durchgeführte Beispiel ist entnommen aus. McCollough, Celeste ; VanAtta, Loche: Statistik programmiert : ein Grundkurs zum Selbstunterricht. -- 2., verbesserte Aufl. -- Weinheim [u.a.] : Beltz, 1971. -- 389 S. : zahlr. graph. Darst. -- Originaltitel: Statistical concepts (1963). -- ISBN: 3-407-28052-1. -- S. 106 - 116]
Eine ausgezeichnete Einführung in moderne beurteilende Statistik für Laien ist:
Swoboda, Helmut <1924 - >: Knaurs Buch der modernen Statistik. -- München [u.a.] : Droemer-Knaur, ©1971. -- 359 S. : mit 315 Ill., graph. Darst. u. Kt.-- (Exakte Geheimnisse). -- ISBN: 3-426-04543-5
Um mögliche Gruppierungen von autorenmäßig zusammengehörigen Einheiten festzustellen, muss man den χ²-Test paarweise auf alle untersuchten Einheiten (d.h. nach Trautmann Bücher des Kautilya) anwenden. Trautmann unterlässt dies aber leider und führt den χ²-Test nur bezüglich der Bücher 2,3 und 7 durch. Dies verleitet ihn dann -- wie wir sehen werden --, Bücher zu Quellengruppen zusammenzufassen, die er nach seiner eigenen Methode nicht zusammenfassen dürfte.
Ich habe deswegen für alle Bücher des Kautilya, die Trautmann untersucht, den χ²-Test paarweise durchgeführt, damit Trautmanns Arbeit auf der Grundlage seiner eigenen Voraussetzungen kritisch gewürdigt werden kann.
Da die Präsentation der Ergebnisse bei Trautmann sehr unübersichtlich und unanschaulich ist, versuche ich in den folgenden Graphiken Trautmanns Ergebnisse augenfälliger darzustellen. Die Gruppierung der Bücher folgt Trautmanns Hypothese.
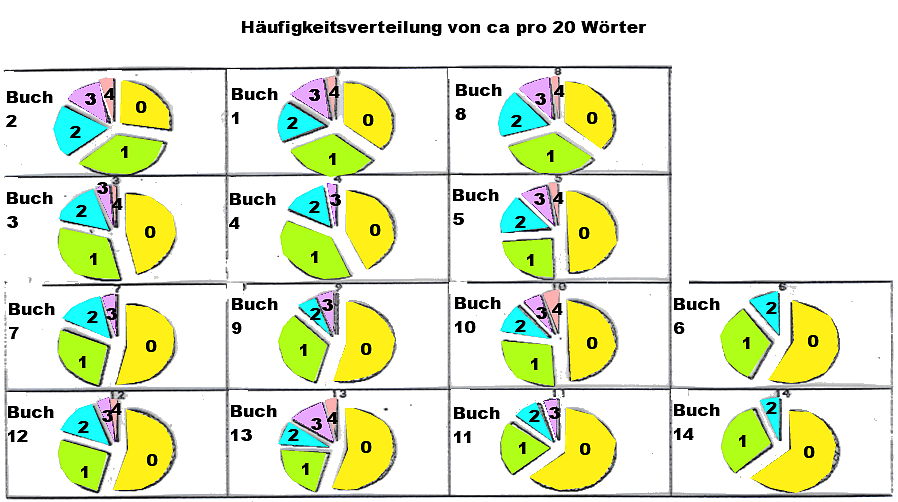
Abb.: Verteilung der relativen Häufigkeit von ca pro Wortblock von 20 Wörter (Datengrundlage:
Trautmann, T. R., 1971, Appendix, Tab. &; S. 210f. und Tab. 4,13 - 16; S. 115 -
122)
Der χ²-Test ergibt bezüglich der relativen Häufigkeit von ca pro Wortblock von 20 Wörtern paarweise zwischen den einzelnen Büchern des Kautilya folgende Werte:
Anordnung der Angaben in den einzelnen Feldern:
| Buch | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 4,8 4 |
11,32 3 *** |
14,84 4 *** |
4,51 4 |
5,26 2 |
32,82 3 **** |
0,64 4 |
16,8 4 *** |
5,34 4 |
6,41 2 * |
8,17 3 * |
9,96 4 * |
18,03 3 **** |
|
| 2 | 4,8 4 |
8,67 9 |
28,65 4 **** |
24,02 3 **** |
15,41 3 *** |
9,7 3 ** |
74,17 4 **** |
2,2 3 |
37,12 3 **** |
14,68 3 *** |
12,67 4 ** |
19,75 3 **** |
24,77 3 **** |
32,16 3 **** |
| 3 | 11,32 3 *** |
28,65 4 **** |
3,49 3 |
2,83 3 |
4,19 3 |
1,62 2 |
9,6 3 |
5,11 3 |
5,43 3 |
0,44 2 |
1,63 2 |
1,3 2 |
13,21 3 *** |
7,99 2 ** |
| 4 | 14,84 4 *** |
24,02 3 **** |
2,83 3 |
10,41 3 ** |
1,67 2 |
12,68 2 *** |
8,2 3 * |
7,69 3 |
7,57 3 |
3,31 2 |
3,6 2 |
20,42 3 **** |
8,19 2 ** |
|
| 5 | 4,51 4 |
15,41 3 *** |
4,19 3 |
10,41 3 ** |
0,4 1 |
6,07 2 * |
3,75 4 |
6,85 4 |
1,5 4 |
1,84 2 |
1,55 3 |
2,92 4 |
9,13 3 * |
|
| 6 | 5,26 2 |
9,7 3 ** |
1,62 2 |
1,67 2 |
0,4 1 |
0,01 1 |
4,47 2 |
0,15 2 |
1,7 2 |
0,19 1 |
0,06 1 |
0,04 1 |
0,31 1 |
|
| 7 | 32,82 3 **** |
74,17 4 **** |
9,6 3 |
12,68 2 *** |
6,07 2 * |
0,01 1 |
3,26 2 |
16,04 2 **** |
5,86 3 |
3,36 2 |
0,00 1 |
0,21 2 |
14,68 3 *** |
4,91 2 |
| 8 | 0,64 4 |
2,2 3 |
5,11 3 |
8,2 3 * |
3,75 4 |
4,47 2 |
16,04 2 **** |
11,15 4 ** |
4,96 4 |
5,56 2 |
5,91 4 |
9,52 4 * |
14,55 3 *** |
|
| 9 | 16,8 4 *** |
37,12 3 **** |
5,43 3 |
7,69 3 |
6,85 4 |
0,15 2 |
5,86 3 |
11,15 4 ** |
3,26 3 |
0,9 2 |
2,91 3 |
8,03 4 |
2,34 2 |
|
| 10 | 5,34 4 |
14,68 3 *** |
0,44 2 |
7,57 3 |
1,5 4 |
1,7 2 |
3,36 2 |
4,96 4 |
3,26 3 |
1,47 2 |
1,36 3 |
2,93 4 |
6,73 2 * |
|
| 11 | 6,41 2 * |
12,67 4 ** |
1,63 2 |
3,31 2 |
1,84 2 |
0,19 1 |
0,00 1 |
5,56 2 |
0,9 2 |
1,47 2 |
0,67 2 |
0,56 1 |
0,0 1 |
|
| 12 | 8,17 3 * |
19,75 3 **** |
1,3 2 |
3,6 2 |
1,55 3 |
0,06 1 |
0,21 2 |
5,91 4 |
2,91 3 |
1,36 3 |
0,67 2 |
5,0 4 |
4,94 2 |
|
| 13 | 9,96 4 * |
24,77 3 **** |
13,21 3 *** |
20,42 3 **** |
2,92 4 |
0,04 1 |
14,68 3 *** |
9,52 4 * |
8,03 4 |
2,93 4 |
0,56 1 |
5,0 4 |
8,4 3 * |
|
| 14 | 18,03 3 **** |
32,16 3 **** |
7,99 2 ** |
8,19 2 ** |
9,13 3 * |
0,31 1 |
4,91 2 |
14,55 3 *** |
2,34 2 |
6,73 2 * |
0,0 1 |
4,94 2 |
8,4 3 * |
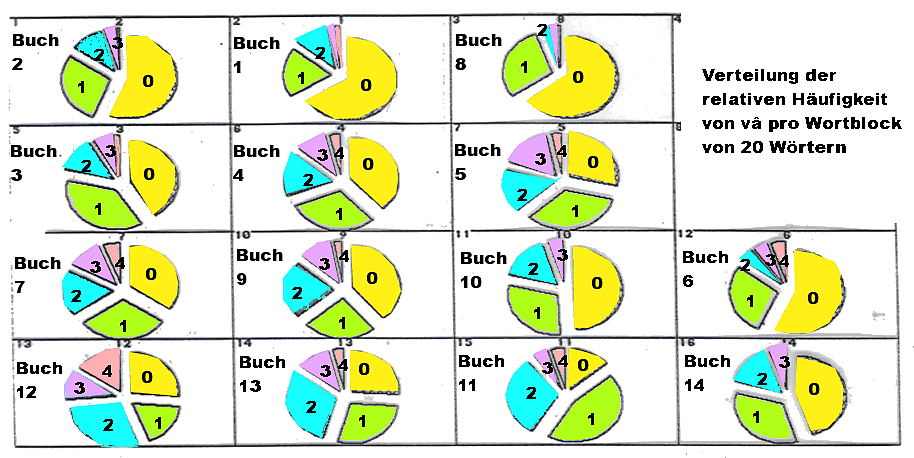
Abb.: Verteilung der relativen Häufigkeit von vâ pro Wortblock von 20
Wörtern (Datengrundlage: Trautmann, T. R., 1971, Appendix, Tab. 6; S. 210f. und
Tab. 4.13 - 16; S: 115 - 122)
Der χ²-Test ergibt bezüglich der relativen Häufigkeit von vâ pro Wortblock von 20 Wörtern paarweise zwischen den einzelnen Büchern des Kautilya folgende Werte:
Anmerkung: Zwischen der ersten und der zweiten Hälfte von Buch 7 besteht ein signifikanter Unterschied (s. Trautmann, T. R., 1971, Tab. 4.13 - 4.14; S. 115f.)
Anordnung der Angaben in den einzelnen Feldern:
| Buch | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 6,07 3 |
24,97 3 **** |
29,87 4 **** |
42,01 4 **** |
0,71 1 |
45,15 4 **** |
5,9 2 |
28,83 4 **** |
5,88 3 |
22,8 2 **** |
50,51 4 **** |
41,12 3 **** |
7,71 3 |
|
| 2 | 6,07 3 |
8,91 6 |
13,26 3 *** |
24,42 3 **** |
37,65 3 **** |
0,0 1 |
46,93 4 **** |
5,63 2 |
27,86 3 **** |
1,80 2 |
13,43 2 *** |
66,18 3 **** |
43,24 3 **** |
2,41 2 |
| 3 | 24,97 3 **** |
13,26 3 *** |
0,333 3 |
5,26 3 |
11,13 3 ** |
1,33 1 |
12,41 4 ** |
16,57 2 **** |
10,9 3 ** |
1,56 2 |
7,82 2 ** |
32,75 3 **** |
18,77 3 **** |
0,29 2 |
| 4 | 29,87 4 **** |
24,42 3 **** |
5,26 3 |
3,14 4 |
3,53 2 |
1,25 4 |
23,8 3 **** |
2,11 4 |
5,54 4 |
5,01 2 |
17,45 4 *** |
6,58 4 |
2,89 3 |
|
| 5 | 42,01 4 **** |
37,65 3 **** |
11,13 3 ** |
3,14 4 |
6,75 2 * |
1,23 3 |
31,47 3 **** |
5,25 4 |
11,37 4 ** |
2,3 2 |
14,35 4 *** |
5,09 4 |
7,36 4 |
|
| 6 | 0,71 1 |
0,0 1 |
1,33 1 |
3,53 2 |
6,75 2 * |
5,19 2 |
2,14 2 |
4,08 2 |
0,57 2 |
9,38 2 *** |
11,48 2 *** |
9,09 2 ** |
0,9 2 |
|
| 7 | 45,15 4 **** |
46,93 4 **** |
12,41 4 ** |
1,25 4 |
1,23 3 |
5,19 2 |
15,57 4 *** |
32,33 3 **** |
4,37 4 |
8,63 3 * |
4,24 2 |
14,9 4 *** |
6,62 3 |
5,25 3 |
| 8 | 5,9 2 |
5,63 2 |
16,57 2 **** |
23,8 3 **** |
31,47 3 **** |
2,14 2 |
32,33 3 **** |
26,42 4 **** |
8,84 2 ** |
26,74 2 **** |
47,54 4 **** |
39,40 4 **** |
9,16 2 ** |
|
| 9 | 28,83 4 **** |
27,86 3 **** |
10,9 3 ** |
2,11 4 |
5,25 4 |
4,08 2 |
4,37 4 |
26,42 4 **** |
5,98 4 |
7,16 3 |
14,93 4 *** |
4,34 4 |
4,46 3 |
|
| 10 | 5,88 3 |
1,80 2 |
1,56 2 |
5,54 4 |
11,37 4 ** |
0,57 2 |
8,63 3 * |
8,84 2 ** |
5,98 4 |
8,96 2 ** |
21,5 4 **** |
12,89 4 ** |
0,26 2 |
|
| 11 | 22,8 2 **** |
13,43 2 *** |
7,82 2 ** |
5,01 2 |
2,3 2 |
9,38 2 *** |
4,24 2 |
26,74 2 **** |
7,16 3 |
8,96 2 ** |
8,66 4 |
3,07 3 |
7,24 2 * |
|
| 12 | 50,51 4 **** |
66,18 3 **** |
32,75 3 **** |
17,45 4 *** |
14,35 4 *** |
11,48 2 *** |
14,9 4 *** |
47,54 4 **** |
14,93 4 *** |
21,5 4 **** |
8,66 4 |
7,77 4 |
18,02 4 *** |
|
| 13 | 41,12 3 **** |
43,24 3 **** |
18,77 3 **** |
6,58 4 |
5,09 4 |
9,09 2 ** |
6,62 3 |
39,40 4 **** |
4,34 4 |
12,89 4 ** |
3,07 3 |
7,77 4 |
9,34 3 * |
|
| 14 | 7,71 3 |
2,41 2 |
0,29 2 |
2,89 3 |
7,36 4 |
0,9 2 |
5,25 3 |
9,16 2 ** |
4,46 3 |
0,26 2 |
7,24 2 * |
18,02 4 *** |
9,34 3 * |
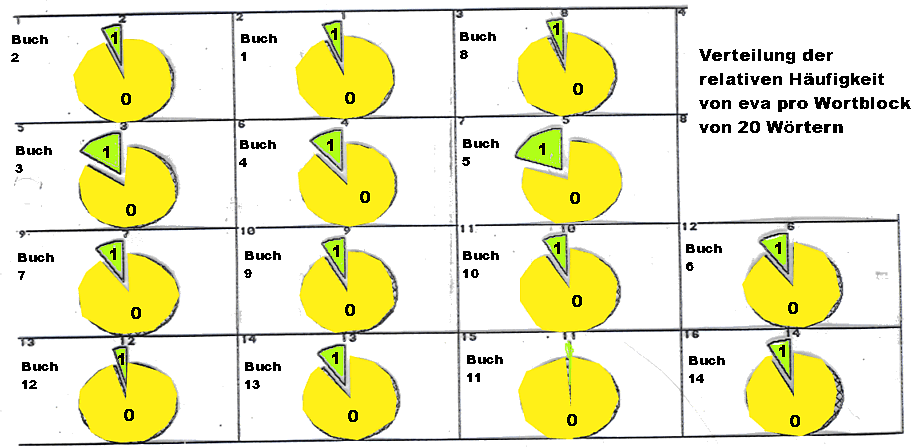
Abb.: Verteilung der relativen Häufigkeit von eva pro Wortblock von 20
Wörtern (Datengrundlage: Trautmann, T. R., 1971, Appendix, Tab. 6; S. 210f. und
Tab. 4.13 - 16; S: 115 - 122)
Der χ²-Test ergibt bezüglich der relativen Häufigkeit von eva pro Wortblock von 20 Wörtern paarweise zwischen den einzelnen Büchern des Kautilya folgende Werte:
Anordnung der Angaben in den einzelnen Feldern:
| Buch | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0,00 | 5,74 ** |
3,77 | 11,39 **** |
-- | 0,85 | -- | 0,24 | -- | -- | -- | 1,46 | -- | |
| 2 | 0,00 | 3,98 3 |
10,43 *** |
5,05 ** |
16,02 **** |
-- | 1,53 | -- | 0,13 | -- | -- | -- | 1,31 | -- |
| 3 | 5,74 ** |
10,43 *** |
0,00 | 0,13 | 1,17 | -- | 2,73 | 2,93 | 3,02 | 1,03 | -- | 3,4 | 0,53 | 1,34 |
| 4 | 3,77 | 5,05 ** |
0,13 | 2,48 | -- | 0,82 | 2,22 | 1,84 | 0,68 | -- | 2,74 | 0,23 | 1,08 | |
| 5 | 11,39 **** |
16,02 **** |
1,17 | 2,48 | -- | 5,87 ** |
6,91 *** |
7,52 *** |
3,89 * |
-- | 7,48 *** |
3,13 | 4,22 * |
|
| 6 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- |
| 7 | 0,85 | 1,53 | 2,73 | 0,82 | 5,87 ** |
-- | 0,12 | 0,35 | 0,11 | 0,0 | -- | 0,63 | 0,02 | -- |
| 8 | -- | -- | 2,93 | 2,22 | 6,91 *** |
-- | 0,35 | 0,14 | 0,33 | -- | -- | 0,95 | -- | |
| 9 | 0,24 | 0,13 | 3,02 | 1,84 | 7,52 *** |
-- | 0,11 | 0,14 | 0,08 | -- | 0,36 | 0,52 | -- | |
| 10 | -- | -- | 1,03 | 0,68 | 3,89 * |
-- | 0,0 | 0,33 | 0,08 | -- | -- | 0,13 | -- | |
| 11 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| 12 | -- | -- | 3,4 | 2,74 | 7,48 *** |
-- | 0,63 | -- | 0,36 | -- | -- | 1,35 | -- | |
| 13 | 1,46 | 1,31 | 0,53 | 0,23 | 3,13 | -- | 0,02 | 0,95 | 0,52 | 0,13 | -- | 1,35 | 0,38 | |
| 14 | -- | -- | 1,34 | 1,08 | 4,22 * |
-- | -- | -- | -- | -- | -- | -- | 0,38 |
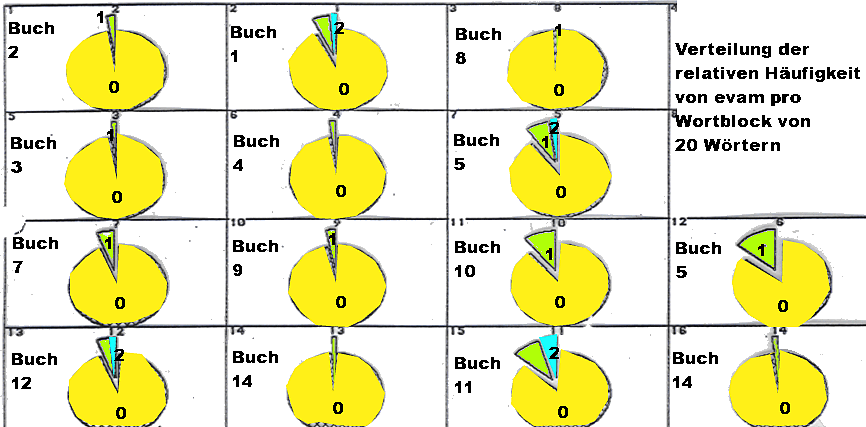
Abb.: Verteilung der relativen Häufigkeit von eva pro Wortblock von 20 Wörtern (Datengrundlage: Trautmann, T. R., 1971, Appendix, Tab. 6; S. 210f. und Tab. 4.13 - 16; S: 115 - 122)
Der χ²-Test ergibt bezüglich der relativen Häufigkeit von evam pro Wortblock von 20 Wörtern paarweise zwischen den einzelnen Büchern des Kautilya folgende Werte:
Anordnung der Angaben in den einzelnen Feldern:
| Buch | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 4,37 * |
6,78 *** |
4,26 * |
0,59 | -- | 0,16 | -- | 2,09 | 0,78 | -- | -- | -- | -- | |
| 2 | 4,37 * |
-- | -- | -- | -- | -- | 2,6 | -- | -- | -- | -- | -- | -- | -- |
| 3 | 6,78 *** |
-- | -- | -- | -- | 4,85 * |
-- | -- | -- | -- | -- | -- | -- | |
| 4 | 4,26 * |
-- | -- | -- | -- | 1,99 | -- | -- | -- | -- | -- | -- | -- | |
| 5 | 0,59 | -- | -- | -- | -- | 1,32 | -- | 4,18 * |
0,03 | -- | 0,95 | -- | -- | |
| 6 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| 7 | 0,16 | 2,6 | 4,85 * |
1,99 | 1,32 | -- | 0,00 | -- | 0,6 | -- | -- | -- | -- | -- |
| 8 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| 9 | 2,09 | -- | -- | -- | 4,18 * |
-- | 0,6 | -- | -- | -- | -- | -- | -- | |
| 10 | 0,78 | -- | -- | -- | 0,03 | -- | -- | -- | -- | -- | 1,14 | -- | -- | |
| 11 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| 12 | -- | -- | -- | -- | 0,95 | -- | -- | -- | 1,14 | -- | -- | -- | ||
| 13 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | |
| 14 | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- |
Der χ²-Test ergibt bezüglich der relativen Häufigkeit von tatra pro Wortblock von 20 Wörtern paarweise zwischen den einzelnen Büchern des Kautilya keine signifikanten Unterschiede. tatra hat also keinen diskriminierenden Wert.
Eine Gesamtübersicht ergibt folgendes Bild der signifikanten Unterschiede zwischen den Büchern 2, 3 und 7 untereinander und zu den anderen Büchern:
Die Sternchen in den Feldern bezeichnen das Signifikanzniveau:
d.h. je mehr Sternchen im gemeinsamen Feld zweier Bücher stehen, umso unwahrscheinlicher ist, dass sie aus der gleichen Grundgesamtheit (vom gleichen Autor) stammen
| Buch | 2 | 1 | 8 | 3 | 4 | 5 | 7 | 9 | 10 | 6 | 12 | 13 | 11 | 14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | ca | *** | *** | ** | *** | *** | ** | ** | *** | *** | ** | *** | |||
| vâ | ** | *** | *** | ** | *** | *** | *** | ** | *** | ||||||
| eva | ** | * | *** | ||||||||||||
| evam | * | ||||||||||||||
| 3 | ca | *** | ** | * | ** | * | |||||||||
| vâ | ** | *** | *** | * | ** | * | *** | *** | * | ||||||
| eva | ** | * | |||||||||||||
| evam | ** | ||||||||||||||
| 7 | ca | *** | *** | *** | * | ** | * | ** | * | ||||||
| vâ | ** | *** | *** | ** | ** | * | * | ** | |||||||
| eva | * | ||||||||||||||
| evam |
In der folgenden graphischen Darstellung werden die Abstände der einzelnen Bücher zu Buch 2,3 bzw. 7, wie sie signifikante Unterschiede in der Indeklinabiliaverteilung ergeben, sichtbar.
Dabei habe ich -- etwas willkürlich -- einen signifikanten Unterschied auf mindestens 5% Niveau mit 1bewertet, einen bei mindestens 1% mit 2, einen bei mindestens 0,1% mit 3. So sind die folgenden Diagramme nur eine Veranschaulichung der Abstände, nicht aber eine genaue Darstellung der tatsächlichen Irrtumswahrscheinlichkeiten bei Verwerfung der Nullhypothese -- unabhängige Wahrscheinlichkeiten multiplizieren sich ja! Doch würde m .E. eine Darstellung dieser Verhältnisse eventuell zu einer Pseudogenauigkeit führen, wenn zuvor nicht die methodischen Probleme genau diskutiert hat, was für meine Zwecke nicht nötig ist.
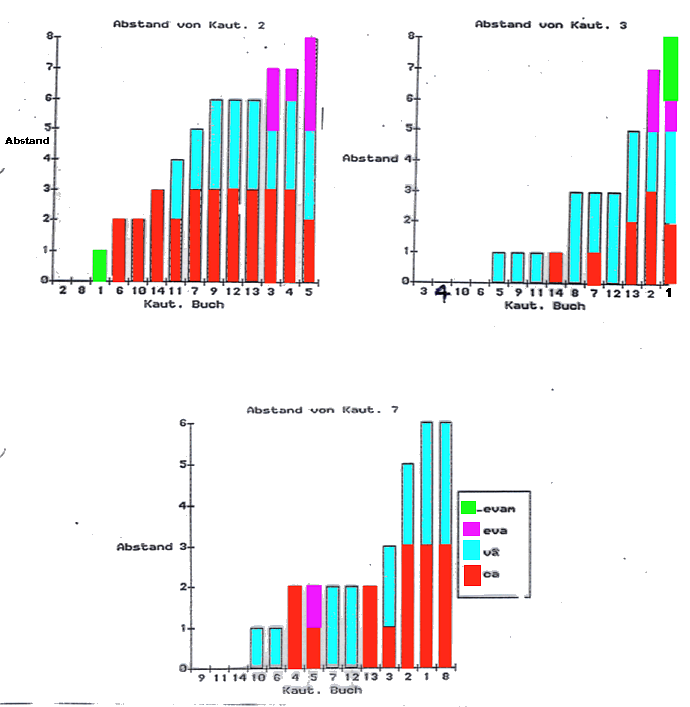
Abb.: Symbolischer Abstand der Bücher des Kautilya aufgrund signifikanter
Unterschiede der Indeklinabiliaverteilung (Datengrundlage: Trautmann, T. R.,
1971, Tab. 4.13 - 16; S: 115 - 122)
Trautmann schließt aus diesen Ergebnissen -- m. E. nicht ganz zu Recht -- "that three hands are discernible in the Artha´sâstra:
(Trautmann, T. R., 1971, S. 118).
Bei der weiteren Quellenscheidung wird Trautmann m. E. inkonsequent, indem er die strikt statistische Quellenscheidung verlässt und plötzlich inhaltliche Aspekte hinzuzieht, statt zu den Konsequenzen seiner Methode zu stehen und eine Aufsplitterung der Artha´sâstra in viel mehr Quellen -- auch quer durch die einzelnen Bücher -- zu akzeptieren.
[Trautmann (S. 118) entschuldigt seine Inkonsequenz damit, dass einzelne Bücher des Kautilya -- besonders Kautilya 6 und 10 -- wahrscheinlich zu kurz seinen, um statistisch ihre Affiliation mit anderen Büchern untersuchen zu können. Mir schein viel eher, dass Trautmann der Mut verlassen hat, konsequent zu sein und eine Aufsplitterung der Quellen hinzunehmen, wie sie vielleicht eine Folge konsequenter Quellenscheidung ist.]
"Looking first at Book 2, the chi-square results offer grave objections to linking it with any other book except for Book 8 (where the results for vâ borders on significance at 5%) and book 1, where the divergences are non-significant, except for evam, with a probability of perhaps three cases in a hundred. Both Books 1 an 8 yield highly significant results wehen compared with Books 3 and 7, and on the principle that it is preferable not to multiply sources beyond need [Hervorhebung von mir], we could initially consider Books 1, 2 and 8 as forming the work of a single author.
Turning now to the affiliation of Book 3, it appears that Book 4 belongs to it, since both Books 2 and 7 reject it. Book 5 shows a slightly significant divergence in respect of vâ when compared with Book 3, and the same for eva and ca, when compared with Book 7, though it clearly cannot be grouped with Book 2. Books 6 and 11 are too short to reach any conclusion, also perhaps Book 14. Of the rest, objections to grouping Book 3 with any other appear in every case but Book 10.
As for Book 7, stands apart from Books 1,2,3,4 and 5. The result for the short Book 6 must be indecisive. Book 8, strangely, is rejected. Book 9 probably belongs to it, and Book 10 may do so, in spite of a slightly signifiant result for vâ.
Books 12 and 13 are rejected by each of Books 2, 3 and 7, and may well form a group of their own, representing a fourth hand in the Artha´sâstra." (Trautmann, T. T., 1971, S. 118 - 119)
Aufgrund χ²-signifikanter Unterschiede der Häufigkeitsverteilungen von ca, vâ, eva und evam und aufgrund inhaltlicher Kriterien schlägt Trautmann folgende Quellenscheidung vor:
| Quelle | Kautilya | Bemerkungen |
|---|---|---|
| Endredaktor | 1.1; 15; 6(?) | Diese Teile trennt Trautmann aus inhaltlichen Erwägungen, nicht aus wortstatistischen ab. Weitere Affiliationen sind wegen der Kürze des Materials statistisch nicht nachweisbar |
| Quelle I | 2; 1; 8(??) | Zu Buch 1 bemerkt Trautmann: "It is
conceivable that Books 1 and 2 belong together, both from the statistical
results as from the fact of their contiguity and the similiarity of subject
matter." (a.a.O., S. 119) Die Zurechnung von Buch 8 zu dieser Quelle erscheint Trautmann (a.a.O., S. 119) nicht sehr sinnvoll." To add Book 8 to that group, however, would make less sense, since it is neither contiguous nor is it obvious that its subject (vices or calamities) fits in well with the first two (ministers and overseers). It is stylistically unique in the extent to which it employs the polemical technique, which is rare in Book 1 and almost absent from Book 2." |
| Quelle II | 3; 4; 5 | "Books 3 and 4 (law and crime) clearly form the core of a second group, to which Book 5 ('secret conduct') might logically be added." (a.a.O., S. 119). Dies, obwohl Buch 3 und Buch 5 sich bezüglich vâ auf einem Signifikanzniveau zwischen 1% und 2,5% unterscheiden! (Ein Niveau, das Nach Trautmann, S. 118, "slightly significant" ist). |
| Quelle III | 7; 9; 10; 6(?) | |
| Quelle IV | 12; 13; 11; 14 | |
| Quelle V (?) | 6(?) |
Das Kriterium Satzlänge kann zur Quellenscheidung nur mit äußersten Einschränkungen angewendet werden. Deswegen verzichtet Trautmann auf entsprechende Untersuchungen. (Trautmann, T. R., 1971, S. 123 - 127).
Eine Untersuchung des Kriteriums "Anzahl der Kompositaglieder" bei Somadeva und Gańge´sa führt Trautmann zur Ansicht:
"Clearly compound length cannot be regarded as a save discriminator without further investigation into its nature and without more testing in control material." (Trautmann, T. R., 1971, S. 130)
Deshalb lässt sich Trautmann auch nicht dadurch beeindrucken, dass ein χ²-Test der Häufigkeitsverteilungen der Anzahl der Kompositaglieder auf 1%-Niveau signifikante Unterschiede zwischen den Büchern 2 und 1, also innerhalb Trautmanns Quelle I, sowie zwischen den Büchern 4 und 4, also innerhalb von Trautmanns Quelle II, ergibt.
Trautmann schließt die betreffenden Untersuchungen mit der Bemerkung:
"Compound-length may prove to be a useful test of authorship in Sanskrit, but as I say, it needs more study." (a.a.O., S. 164)
Deshalb verzichte ich hier auf eine Sekundäranalyse von Trautmanns Daten (Trautrmann, T. R., 1971, Appendix Tab. 7; S. 212f.).
Nach Trautmann sind die Verfasser der Quellen die "früheren Gelehrten" (pûrvâcârya) von Kautilya 1.1.1 (Trautmann, T. R., 1971, S. 174).
Meyer, Johann Jakob <1870-1939>: Über das Wesen der altindischen Rechtsschriften und ihr Verhältnis zu einander und zu Kautilya. -- Leipzig : Harrassowitz, 1927. -- 440 S.
nachzuweisen. Auch bei einer solchen Methode der Kompilation können stilistische Unterschiede zwischen Großkomplexen entstehen: Die Intensität der Benutzung der einzelnen Quellen und Überlieferungen kann unterschiedlich sein. Auch kann die Verknüpfung unterschiedlicher Quellen eine unterschiedliche Verteilung von z.B. ca ("und") und vâ ("oder") bedingen.
Ich halte dies für die Hautschwäche von Trautmanns Arbeit. Das Artha´sâstra macht auf mich nicht den Eindruck, dass sein Kompilator so unintelligent vorgegangen wäre. Auf alle Fälle bleibt Trautmanns Modell eine leere Spekulation, so lange uns nicht einige der Quellen Kautilyas vorliegen: denn bis dann kann eine alternative Untersuchen nach Meyers Modell nicht methodisch sauber durchgeführt werden.
Unter Trautmanns eigenen Voraussetzung müsste man also mindestens drei Quellen mehr annehmen.
Zu Kapitel 4: "Wörter und Sachen": Hartmuth Scharfe